Day 7: Dense Embedding — Capturing Semantic Meaning with Vector Representations
Day 7: Dense Embedding — Capturing Semantic Meaning with Vector Representations
 Parathan Thiyagalingam
Parathan Thiyagalingam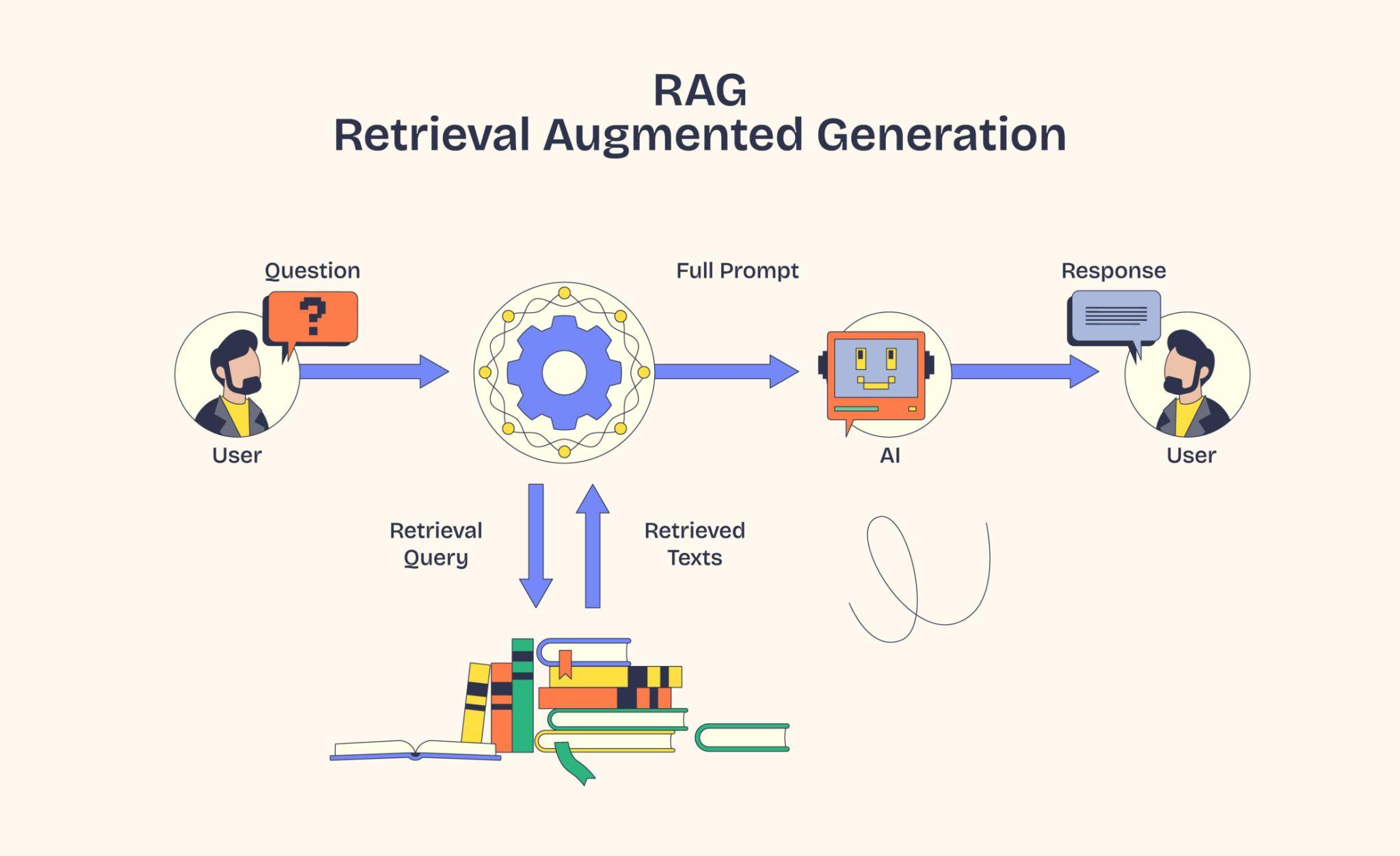
Day 6 on Embeddings — Semantic Similarity, Cosine, and Dense vs Sparse closed with the dense-versus-sparse split and a small Ollama demo. Today we slow down on the dense side specifically. The class went deeper into what "dense" actually means as a vector shape, where dense embeddings come from, the family of similarity measures beyond cosine, and a side-by-side comparison with sparse embeddings in code.
This blog post is a daily learning summary of my 40 Day RAG class from Syed Jaffer of Parotta Salna.
Terms Used Today
- Dense Embedding: A vector where (almost) every dimension carries some meaning. All values are continuous floats, most are non-zero.
- Sparse Embedding: A vector with thousands of dimensions where almost all values are zero. Each non-zero position usually maps to one word in the vocabulary.
- One-Hot Encoding: The simplest sparse representation. A 1 in the slot for the present word, 0 everywhere else. Frequency-based, no notion of meaning.
- Continuous Values: Real numbers like 0.123 or −0.501. Dense embeddings are full of these. Sparse ones mostly are not.
- Cosine Similarity: The angle between two vectors. Met on Day 6 on Embeddings — Semantic Similarity, Cosine, and Dense vs Sparse.
- Euclidean Distance: The straight-line distance between two points in space. The geometry-class measure.
- Dot Product: The sum of products of paired vector components. Big when two vectors point in the same direction and are large.
- Hybrid Search: Combining sparse (BM25) and dense (vector) retrieval into one ranking. OpenSearch is a common tool that does this.
- Transformer Encoder: The "reading" half of a Transformer model. The part that produces embeddings.
- nomic-embed-text, all-MiniLM-L6-v2: Two small open embedding models we will keep using in the demos.
1. From Sparse to Dense:
Day 6 on Embeddings — Semantic Similarity, Cosine, and Dense vs Sparse introduced both families side by side. Sparse for exact word matching (TF-IDF, BM25, ISBN-style lookups), dense for semantic search. The two are often combined into hybrid search in production, with OpenSearch being a common platform that runs BM25 and vector search together over the same index.
 Today's class zoomed in on the dense half. What does "dense" actually mean? Where do dense embeddings come from? And how do we measure how close two of them are?
Today's class zoomed in on the dense half. What does "dense" actually mean? Where do dense embeddings come from? And how do we measure how close two of them are?
2. What Makes an Embedding "Dense":
The shortest definition. A dense embedding is a vector of continuous values, where (almost) every dimension carries some piece of meaning.
 A small concrete contrast.
A small concrete contrast.
- One-hot encoding gives
[0, 0, 0, 1, 0, 0]. One position is "on" because one word is present. The vector is mostly zero. There is no concept of similarity, the slot is either occupied or empty. We touched on this earlier in the class as the simplest sparse representation, frequency-based at the limit. - TF-IDF / BM25 gives something like
[0, 0, 0.7, 0, 0, 1.4, 0, ...]. Still mostly zeros, but the non-zero positions are weighted by how informative each word is. Sparse in shape, statistical in spirit. - Dense embedding gives
[0.123, -0.501, 0.882, 0.044, -0.317, ...]. Hundreds or thousands of dimensions, every position a real number, most of them non-zero. None of the dimensions has a human-readable label. Each one carries a slice of the meaning, learned from training.
A small thought to sit with. Dense embeddings are unintuitive because no individual dimension is interpretable. Dimension 47 is not "royalty" and dimension 312 is not "doctor". The meaning is distributed across the whole vector. We do not read embeddings, we measure distances between them.
3. Where Dense Embeddings Come From:
Modern dense embeddings come from large language models, specifically the encoder part of a Transformer.
The shape.
A piece of text goes in.
The Transformer encoder runs and produces internal representations for every token.
A pooling step (usually mean-pooling or a special
[CLS]token) collapses those token representations into a single fixed-length vector. That vector is the embedding. The class examples.
The class examples.nomic-embed-text. A small open-source model, common with Ollama for local embedding. The default in this series.
all-MiniLM-L6-v2 (MiniLM). Tiny, fast, very widely used as a baseline. Distilled from larger BERT-class models.
Many others (OpenAI's
text-embedding-3, Cohere Embed, Gemini's embedding model, Qwen3 embeddings, the GPT-OSS family). All return dense vectors. Sizes range from 384 dimensions (MiniLM) to 1536 or higher.
A small but important point. Every embedding model lives in its own coordinate system. A 768-dimension vector from nomic-embed-text and a 768-dimension vector from MiniLM are not comparable, even though they look the same shape. We come back to this in section 6.
4. Three Ways to Measure Closeness:
Day 6 on Embeddings — Semantic Similarity, Cosine, and Dense vs Sparse introduced cosine similarity as the default in RAG. The class today expanded the menu. Three measures worth knowing on sight.
- Cosine Similarity. Measures the angle between two vectors. Range −1 to 1. Ignores vector length, only direction matters. The default in semantic search because chunks of different sizes compare fairly.
- Euclidean Distance. The straight-line distance between two points in vector space, exactly like geometry class. Sensitive to vector length. Lower is closer. Common when vectors are already normalised, in which case Euclidean and cosine give the same ordering.
- Dot Product. The sum of products of paired components. Goes up when two vectors point in the same direction and are large. Some embedding models (notably OpenAI's) are tuned so that dot product works directly without a normalisation step.
 A useful distinction. Cosine cares only about direction. Euclidean cares about distance. Dot product cares about both. For most RAG with semantic vectors, the three give very similar top-K rankings, especially when the embeddings are normalised to unit length. The choice often comes down to what the vector database expects.
A useful distinction. Cosine cares only about direction. Euclidean cares about distance. Dot product cares about both. For most RAG with semantic vectors, the three give very similar top-K rankings, especially when the embeddings are normalised to unit length. The choice often comes down to what the vector database expects.
5. Why "Weight Loss" and "Fat Loss" Live in the Same Neighbourhood:
A small example the class used. "Weight loss" and "fat loss" are technically different concepts. Strictly, you can lose weight without losing fat (water, muscle). Yet a good dense embedding model places them very close in vector space.
Why. The training data shows the two phrases used in similar contexts across millions of documents. Fitness articles, medical guidelines, marketing copy, forum posts. The model has no formal definition of either term. It has the company they keep. And the company is almost identical.
This is the entire point of dense embeddings. They cluster things that mean roughly the same to people, even when the words are different. That property is what makes them useful for question-answering RAG, where users phrase questions in ways the source documents do not.
 A small thought to sit with. The same property is also a source of subtle bugs. The model will happily decide that weight loss and fat loss should match, but it might also decide that lose weight and gain weight are quite close (they share most of their context), which is the opposite of what we want. Dense embeddings are powerful, not precise. For exact disambiguation, we lean on sparse and keyword search alongside.
A small thought to sit with. The same property is also a source of subtle bugs. The model will happily decide that weight loss and fat loss should match, but it might also decide that lose weight and gain weight are quite close (they share most of their context), which is the opposite of what we want. Dense embeddings are powerful, not precise. For exact disambiguation, we lean on sparse and keyword search alongside.
6. The Same-Model Rule:
A non-negotiable rule for any vector-based RAG pipeline. Use the same embedding model for indexing and for the query.
The reason. Each model maps text into its own internal coordinate system. Two models, even with the same output dimension, will place the same sentence at completely different points. If we embed our chunks with nomic-embed-text and our queries with MiniLM, the cosine similarity scores are mathematically defined but practically meaningless. The system will return nonsense.
The practical version.
- Pick the embedding model at the start of the project.
- Record it (model name and version) alongside every stored chunk.
- Use the same model in the query pipeline.
- If you ever change the model, you must re-embed all stored chunks. Mixed-model indexes are a slow-burn bug that is painful to debug.
 A small but useful pattern. Most vector databases let you store the embedding-model metadata next to each vector for exactly this reason. When the inevitable model upgrade comes, the metadata makes the re-embed work tractable.
A small but useful pattern. Most vector databases let you store the embedding-model metadata next to each vector for exactly this reason. When the inevitable model upgrade comes, the metadata makes the re-embed work tractable.
7. Sparse vs Dense, Side by Side (With Code):
The class wrapped up with a small comparison snippet. Same three sentences, embedded twice. Once with a sparse vectoriser, once with a dense model.
from sklearn.feature_extraction.text import TfidfVectorizer
import ollama
import numpy as np
docs = [
"weight loss tips for beginners",
"fat loss workout routine",
"best programming languages 2025",
]
# --- Sparse: TF-IDF ---
sparse_vec = TfidfVectorizer()
sparse = sparse_vec.fit_transform(docs).toarray()
print("Sparse shape:", sparse.shape)
print("Vocabulary size:", len(sparse_vec.vocabulary_))
print("First doc (sparse):", sparse[0])
print("Non-zero positions in first doc:", int(np.count_nonzero(sparse[0])))
# --- Dense: nomic-embed-text via Ollama ---
def dense_embed(text):
return ollama.embeddings(model="nomic-embed-text", prompt=text)["embedding"]
dense = np.array([dense_embed(d) for d in docs])
print("\nDense shape:", dense.shape)
print("First doc (dense, first 8 dims):", dense[0][:8])
print("Non-zero positions in first doc:", int(np.count_nonzero(dense[0])))
What to notice in the output.
- Sparse shape is
(3, vocab_size). The vocabulary here is around 11 unique words across the three sentences, so each vector is 11 long. Each row has only a handful of non-zero values (the words actually present in that sentence). Two semantically close sentences ("weight loss tips..." and "fat loss workout...") share no vocabulary, so their sparse vectors are nearly orthogonal. A pure-sparse search would not know they are related. - Dense shape is
(3, 768)for nomic-embed-text. Every dimension is a continuous float. Every position is non-zero. And cosine similarity between the first two sentences comes out high (often above 0.7), even though they share no words. The third sentence ("best programming languages 2025") sits far away from both.-1779720773693.png) That gap, sparse declaring two sentences unrelated, dense declaring them close, is the entire reason dense retrieval was invented.
That gap, sparse declaring two sentences unrelated, dense declaring them close, is the entire reason dense retrieval was invented.
8. If This Came In An Interview:
- What is a dense embedding? A vector of continuous values where (almost) every dimension carries some piece of meaning. Hundreds or thousands of dimensions, mostly non-zero.
- How is dense different from sparse? Sparse vectors are mostly zeros and map directly to vocabulary words. Dense vectors are mostly non-zero and have no individually interpretable dimensions. Meaning is distributed across the whole vector.
- Where do dense embeddings come from? The encoder part of a Transformer. Text goes in, the encoder produces token representations, a pooling step collapses them into a single fixed-length vector.
- Name three similarity measures used with embeddings. Cosine similarity (angle), Euclidean distance (straight-line), dot product (sum of products).
- When do cosine and Euclidean give the same ranking? When vectors are normalised to unit length. Then the angle and the distance are monotonically related.
- Can I use one embedding model for indexing and another for queries? No. Each model has its own coordinate system. Mixing them produces meaningless similarity scores. Pick one model, use it for both, and re-embed everything if you ever switch.
- Why does a model place "weight loss" and "fat loss" close together? Because in the training corpus, the two phrases appear in nearly identical contexts. The model learned that contextual similarity and encoded it as geometric closeness.
- What is hybrid search? Combining sparse (BM25) and dense (vector) retrieval into one ranking. OpenSearch and Elasticsearch both support this pattern.
9. Summing It Up:
If we remember one thing from today, it is this: a dense embedding is a vector of continuous values, produced by the encoder part of a Transformer, where meaning is distributed across all dimensions. Cosine, Euclidean and dot product are the three standard ways to measure how close two of them are. The same embedding model has to be used for both indexing and querying, because each model lives in its own coordinate system. Dense embeddings cluster semantically-related text together (weight loss and fat loss) in ways that no sparse method can match, which is exactly why they dominate modern RAG.
Coming Up on Day 8 on Sparse Embeddings in RAG – Understanding Token-Based Semantic Retrieval
We have closed out the dense side properly. Tomorrow we flip back to the sparse half and build it up from the ground. One-hot encoding, token counts with Counter, then Term Frequency from scratch on both a toy sentence and a real movie dataset. IDF, TF-IDF, BM25, and the hybrid search that ties sparse and dense together follow on Day 9.
That's all for today. Let's meet up again tomorrow with Day 8.
Thanks for reading.
Cheers!