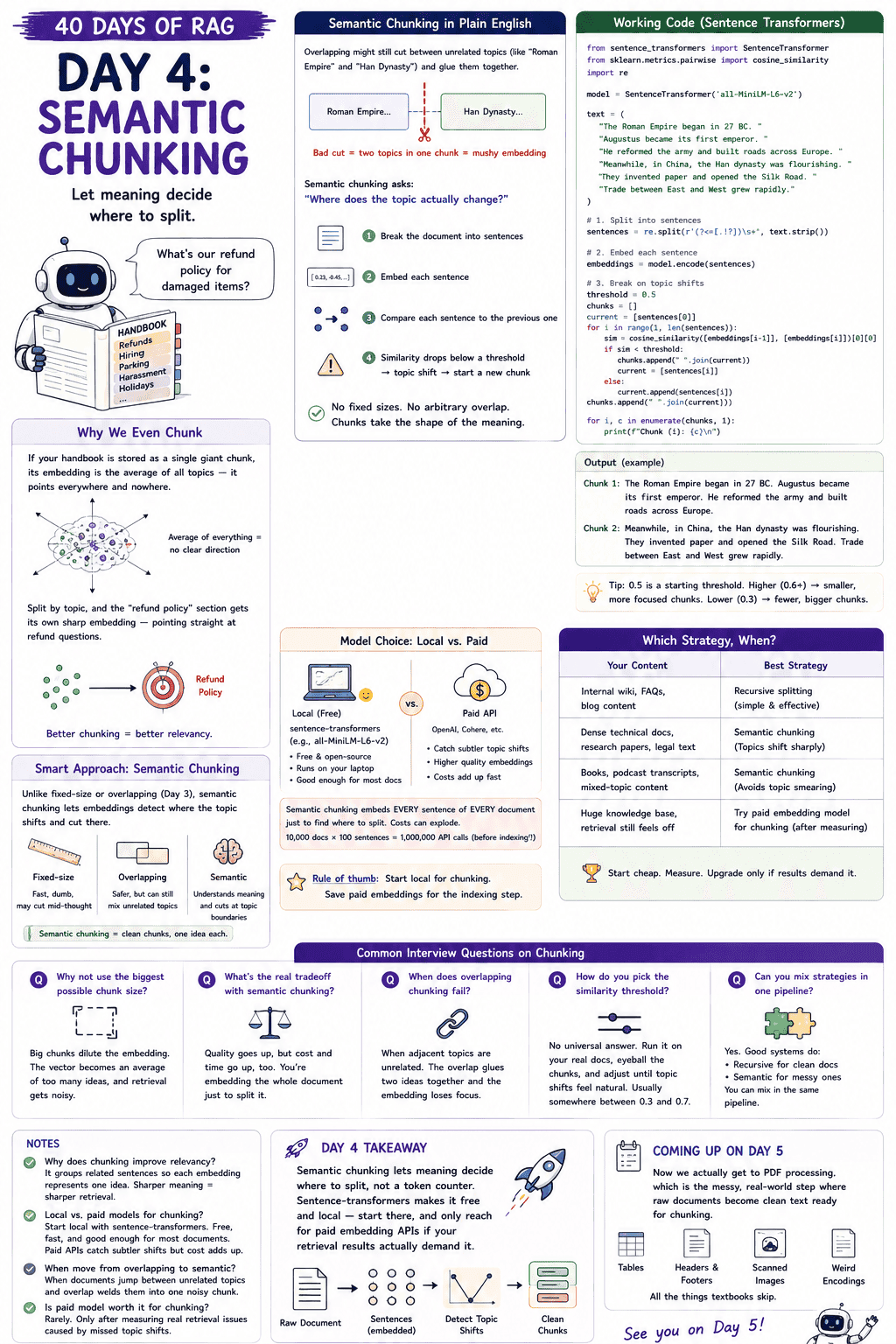
Day 4: Semantic Chunking — When Meaning Decides Where to Split
Smart chunking decides RAG quality. Learn semantic chunking with Sentence Transformers, when to use embedding-based chunking, and the cost tradeoffs that matter.
 Parathan Thiyagalingam
Parathan Thiyagalingam
Day 3 is called "semantic chunking", but I only glanced at it. Today, we slow down. The full recipe: working code with sentence-transformers, where the similarity threshold actually comes from, and when the smarter strategy is worth its cost.
This blog post is a daily learning summary of my 40-day RAG class from Syed Jaffer of Parotta Salna.
Terms Used Today
- Semantic chunking: Splitting text where the meaning shifts, instead of at fixed sizes or arbitrary intervals.
- Sentence-transformers: A free, open-source library for running embedding models locally.
- Similarity threshold: The cutoff (e.g., 0.5) below which two adjacent sentences are treated as a topic shift, triggering a new chunk.
- all-MiniLM-L6-v2: A small, fast, free sentence-embedding model. A common default for local semantic chunking.
1. Why We Even Chunk:
Picture this. We ask our RAG bot:
"What's our refund policy for damaged items?"
If our handbook is stored as one giant chunk, its embedding is the average of every topic in the book. Refunds, hiring, parking, harassment policy, holidays. That vector points everywhere and nowhere.
Split the same handbook by topic, and the "refund policy" section gets its own sharp embedding pointing straight at refund questions. Retrieval lights up.
Chunking groups related sentences so each embedding has one clear meaning the search can latch onto.
That is the whole point. Better chunking, better relevancy.
2. Why Overlap Sometimes Isn't Enough:
Day 3 introduced fixed-size, overlapping, and semantic chunking. Today we slow down on the third.
Here is the issue with overlapping chunks. Sometimes the overlap still doesn't make sense. If the window happens to cut between "Roman Empire" and "Han dynasty", we have stitched two unrelated topics into one chunk and called it context. The embedding goes back to being mush.
Semantic chunking fixes this by asking a different question:
"Where does the topic actually change?"
3. Semantic Chunking, in Plain English:
The recipe:
- Break the document into sentences.
- Embed each sentence.
- Walk through them one by one, comparing each to the previous.
- When the similarity drops below a threshold, that is a topic shift. Start a new chunk.
No fixed sizes. No arbitrary overlap. Chunks end up whatever shape the meaning takes.
4. Working Code with Sentence Transformers:
sentence-transformers is a free open-source library that runs embedding models on our laptop. No API key. No per-token cost.
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import re
model = SentenceTransformer('all-MiniLM-L6-v2')
text = (
"The Roman Empire began in 27 BC. "
"Augustus became its first emperor. "
"He reformed the army and built roads across Europe. "
"Meanwhile, in China, the Han dynasty was flourishing. "
"They invented paper and opened the Silk Road. "
"Trade between East and West grew rapidly."
)
# 1. Split into sentences
sentences = re.split(r'(?<=[.!?])\s+', text.strip())
# 2. Embed each sentence
embeddings = model.encode(sentences)
# 3. Break on topic shifts
threshold = 0.5
chunks = []
current = [sentences[0]]
for i in range(1, len(sentences)):
sim = cosine_similarity([embeddings[i-1]], [embeddings[i]])[0][0]
if sim < threshold:
chunks.append(" ".join(current))
current = [sentences[i]]
else:
current.append(sentences[i])
chunks.append(" ".join(current))
for i, c in enumerate(chunks, 1):
print(f"Chunk {i}: {c}\n")
Run it, and we get something like the following:
Chunk 1: The Roman Empire began in 27 BC. Augustus became its first emperor. He reformed the army and built roads across Europe.
Chunk 2: Meanwhile, in China, the Han dynasty was flourishing. They invented paper and opened the Silk Road. Trade between East and West grew rapidly.
Two clean chunks. One per topic. No mid-thought cuts. No token count to babysit.
Tip:
0.5is a starting threshold. Tighter (0.6+) gives smaller, more focused chunks. Looser (0.3) gives fewer, bigger ones. Tune it on your data.
5. Local vs Paid Embedding Models for Chunking:
We can run semantic chunking with a local model (like all-MiniLM-L6-v2 the one above, which is free and runs fine on a laptop) or with a paid API (OpenAI's text-embedding-3-large, Cohere, etc.).
The better-paid models catch slightly subtler topic shifts. But here is the catch. Semantic chunking embeds every sentence of every document just to figure out where to split. A small RAG with 10,000 documents averaging 100 sentences each = 1,000,000 API calls before we have embedded a single query.
Rule of thumb: start with a local sentence-transformer for chunking. Save paid embeddings for the actual indexing step where they earn their keep.
6. Which Strategy, When?
A quick guide based on what we are working with:
- Internal wiki, FAQs, blog content. Recursive splitting is fine. Don't overthink it.
- Dense technical documents, research papers, and legal text. Semantic chunking. Topics shift sharply, and we want clean cuts.
- Books, podcast transcripts, mixed-topic content. Semantic chunking shines. Overlapping would smear topics together.
- Huge knowledge base, but retrieval still feels off. Try a paid embedding model for the chunking step, but only after measuring that the local one is the actual bottleneck.
Start cheap. Measure. Upgrade only if results demand it.
7. If This Came In An Interview:
- Why not just use the biggest possible chunk size? Big chunks dilute the embedding. The vector becomes an average of too many ideas, and retrieval gets noisy.
- What is the real tradeoff with semantic chunking? Quality goes up, but cost and time go up, too. We embed the entire document, then split it before we ever embed it for storage.
- When does overlapping chunking fail? When adjacent topics are unrelated. The overlap glues two ideas together into one chunk, and the embedding loses focus.
- How do you pick the similarity threshold? No universal answer. Run it on real docs, eyeball the chunks, and adjust until topic shifts feel natural. Usually somewhere between 0.3 and 0.7.
- Can you mix chunking strategies within a single pipeline? Yes, and good systems do—recursive splitting for clean, structured docs and semantics for the messy ones—the same pipeline.
8. Summing It Up:
If we remember one thing from today, it is this: semantic chunking lets meaning decide where to split, not a token counter. Sentence-transformers makes it free and local, so start there and only reach for paid embedding APIs if retrieval results actually demand it.
Coming Up on Day 5
Now we actually get to PDF processing, the messy real-world step where raw documents become clean text ready for chunking. Tables, headers, footers, scanned images, weird encodings. All the things textbooks skip. We will also pick up two more chunking flavours along the way: sliding chunks and token-based sizing.
That's all for today. Let's meet up again tomorrow with Day 5.
Thanks for reading.
Cheers!