Day 3: Bias-Variance Tradeoff — Why Models Fail
Day 3 on Bias-Variance Tradeoff
 Parathan Thiyagalingam
Parathan Thiyagalingam
On Day 2, we met overfitting and underfitting as the two failure modes of ML. Today we put both of them inside one mental model that explains every modelling decision we will ever make. This idea is called the bias-variance tradeoff, and it is the kind of concept that, once it clicks, changes how we look at every algorithm from here on.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Bias: How wrong the model tends to be regardless of what training data we give it. A model too simple to capture the truth (like a straight line trying to fit a curvy pattern) has high bias. Causes underfitting.
- Variance: How much the model's predictions change when we retrain it on slightly different data. A model that memorises training noise has high variance. Causes overfitting.
- Irreducible noise: The randomness in the real world that no model can remove.
- Tradeoff: Lowering bias usually raises variance, and vice versa.
1. The Dart Board Picture:
Imagine four friends throwing ten darts each at a board. The bullseye is the true answer.
- Friend A: All darts land tightly clustered, but far from the bullseye. Consistent, but consistently wrong.
- Friend B: Darts scattered everywhere, but the average position is on the bullseye. Right on average, wildly inconsistent.
- Friend C: All darts clustered tightly around the bullseye. The dream.
- Friend D: Darts scattered everywhere AND the average is off. Catastrophe.
We can think of every ML model as one of these dart throwers. The "throws" are what the model would predict if we trained it on different chunks of data drawn from the same population.

| Thrower | Bias | Variance | Translation |
|---|---|---|---|
| A | High | Low | Underfitting |
| B | Low | High | Overfitting |
| C | Low | Low | The sweet spot |
| D | High | High | Worst of both worlds |
2. Defining Bias and Variance in Plain English:
Bias is how wrong the model is on average across any training data we might give it. A simple model (a straight line trying to fit a curvy pattern) has high bias because no amount of data lets it bend to the truth.
Variance is how much the model's predictions wobble when we retrain it on slightly different data. High variance means the model is over-sensitive to the specific examples it saw, and a small change in those examples produces a large change in the model.
For example, a linear model trying to fit a curvy relationship will have high bias because it is too simple. A deep decision tree memorising every training point will have high variance because it is too jumpy.
Here is a crucial distinction that often confuses beginners. High bias and high variance feel different when we look at our scores.
- High bias hurts both training and test scores. The model is structurally too simple. Even the training set looks bad, because the model cannot fit it well.
- High variance hurts only the test score. The training score looks great (the model memorised), but new data exposes the rot.
If we remember nothing else from today, it is this: bias is being wrong everywhere, variance is being wrong specifically on data the model has not seen.
3. The Tradeoff:
Here is the painful part. We usually cannot lower both at the same time.
- Make the model more complex → bias goes down, variance goes up.
- Make the model simpler → bias goes up, variance goes down.
It is like a seesaw. Push one side, the other rises. Most ML choices (model complexity, regularisation strength, tree depth, the number of neighbours in KNN) are really about choosing where to sit on this seesaw.
A small thought to sit with. Every hyperparameter we will ever tune in this series is, at heart, just a knob that moves us along this seesaw. We are always searching for the spot where total error is smallest.
4. The Error Equation (Just for Intuition):
We do not need to memorise this, but it makes the picture click.
Total error = Bias² + Variance + Irreducible noise
- Bias² is the wrongness we can fix by being smarter.
- Variance is the jumpiness we can fix by being calmer.
- Irreducible noise is the randomness in the world. Always there. We cannot fix it.
A tiny worked example. Say a model has bias 0.3, variance 0.2, and irreducible noise 0.1.
Total error works out to 0.3² + 0.2 + 0.1 = 0.09 + 0.2 + 0.1 = 0.39.
If we shrink bias to 0.1 (bias² becomes 0.01) but variance jumps to 0.4 (because the model is now more flexible), total becomes 0.01 + 0.4 + 0.1 = 0.51. We chased lower bias and made things worse. That is the tradeoff in numbers.

The goal of any model is not zero error. It is the smallest error we can get given those three pieces.
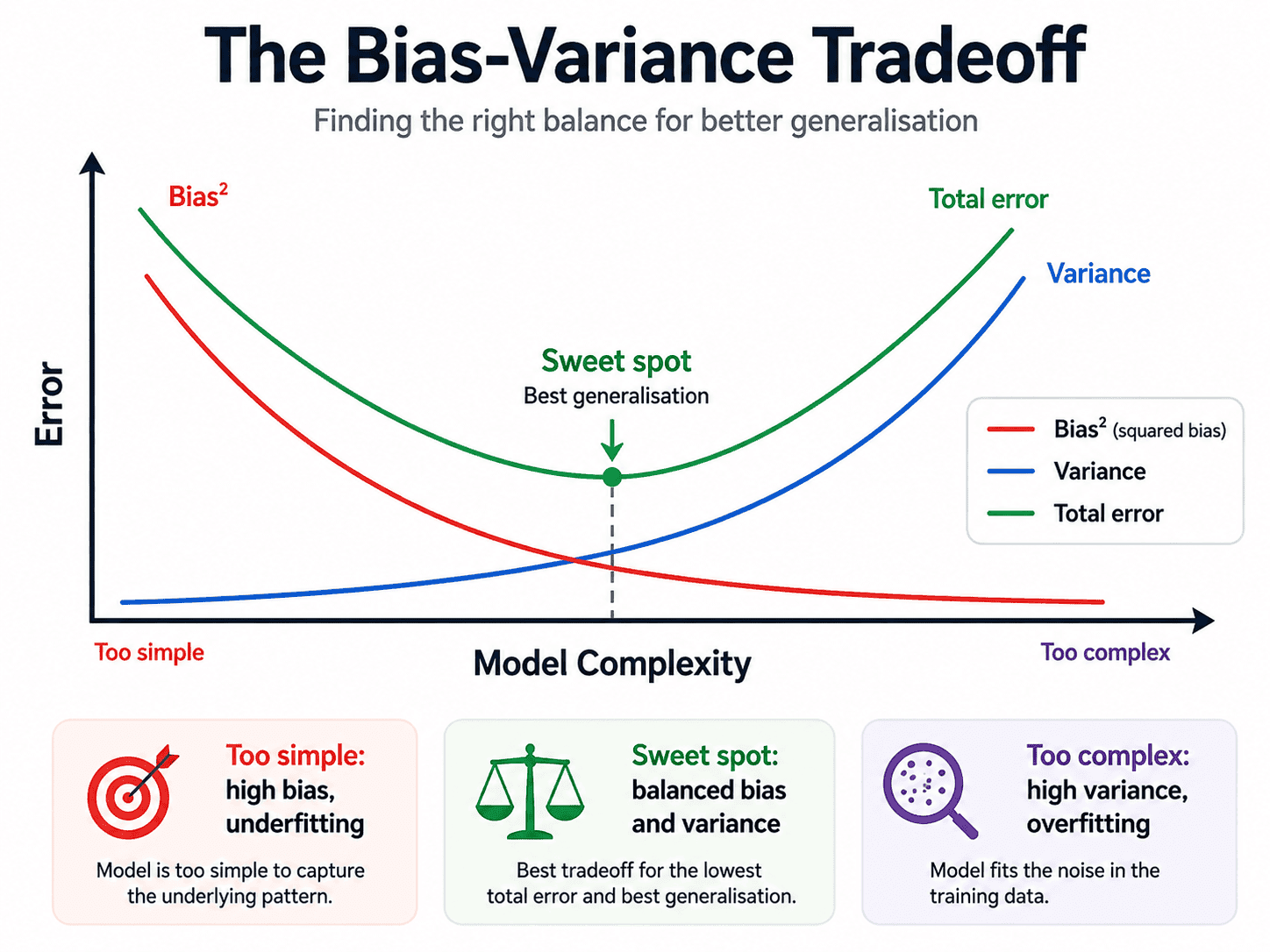
If we plot the error as we crank up model complexity from left (simple) to right (complex):
- Bias drops steeply.
- Variance rises steeply.
- Total error dips down, hits a minimum, then climbs again.
That minimum is the sweet spot. Almost every hyperparameter we tune is just a search for that minimum.
5. How Different Algorithms Sit on the Seesaw: - We will go deeper on these algorithms in future
A rough mental map (we will meet each algorithm in detail later this series).
- Linear and Logistic Regression: naturally high bias, low variance. Great when the world really is roughly linear.
- Deep Decision Trees: naturally low bias, high variance. They will memorise anything we let them.
- KNN with small k: low bias, high variance.
- KNN with large k: high bias, low variance.
- Random Forest and XGBoost: clever ensembles that lower variance without raising bias much. Part of why they are so loved.

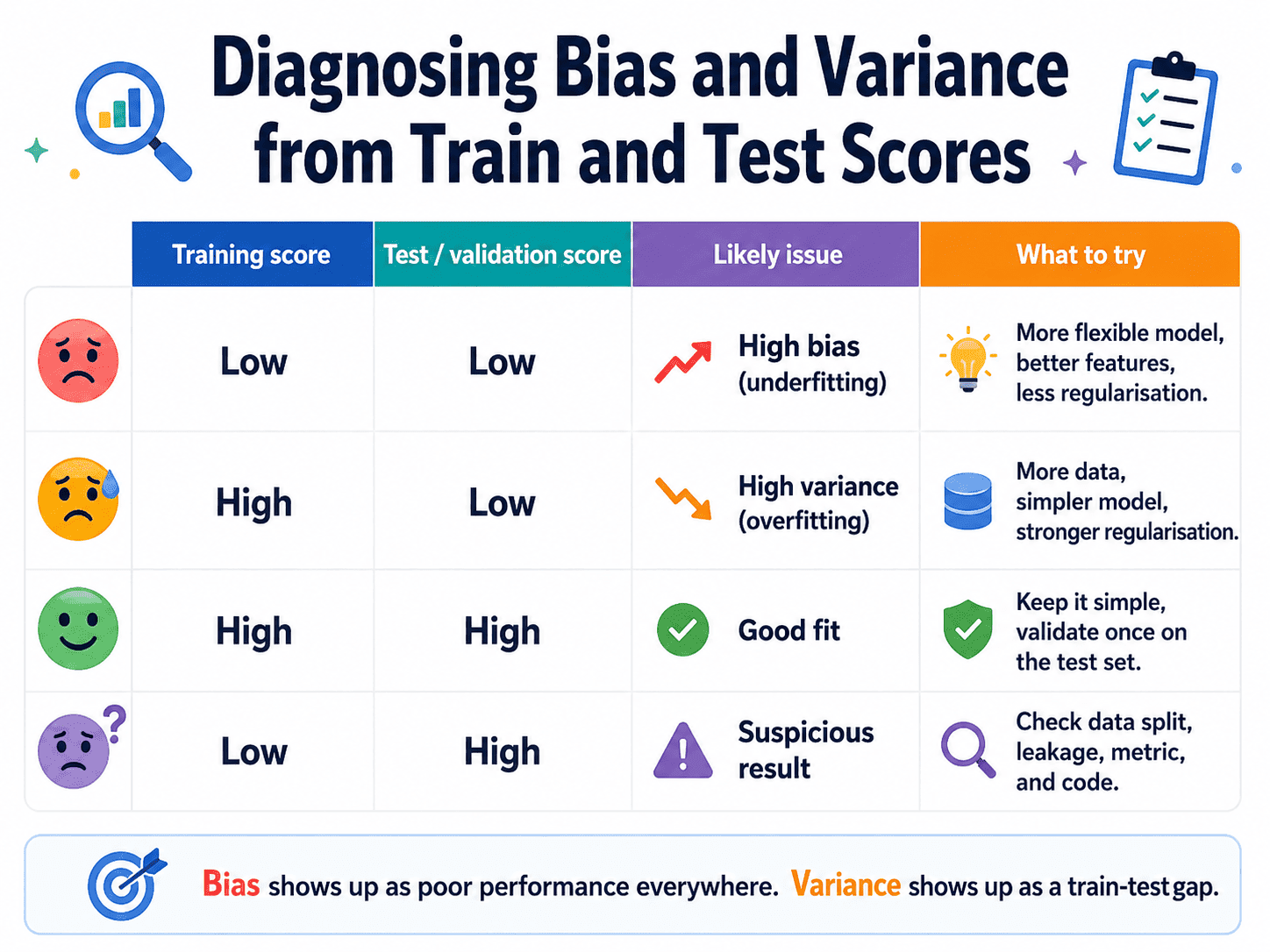
6. How to Diagnose Bias vs Variance in Practice:
Look at training and test scores side by side.
| Train score | Test score | Diagnosis | Fix direction |
|---|---|---|---|
| Low | Low | High bias (underfit) | More complex model, more features |
| High | Low | High variance (overfit) | Simpler model, more data, regularise |
| Close & high | Close & high | Sweet spot | Don't break what's working |
| Low | High | Buggy split. Check code. | Investigate |
That table is genuinely useful, both in real projects and in interviews.
A short thought experiment. Imagine we train a model and get train accuracy 95% and test accuracy 92%. A friend says "add more features and more layers, it'll improve!" What is our gut reaction? Be careful. The gap is small. We are near the sweet spot. Cranking complexity now would lower bias slightly but raise variance a lot, and we would probably make the test score worse, not better. The signal here is to stop, because this is fine.
7. A Few Common Confusions Cleared:
- Is high variance the same as overfitting? Practically yes. High variance means the model changes wildly with small data changes, which is the mechanism of overfitting.
- Can a model have both high bias and high variance? Yes, a bad model on bad data. Rare with a sensible setup, but possible.
- Is "irreducible error" actually irreducible? Given the features we have, yes. We can sometimes reduce it by adding better features (more signal), but we cannot reduce inherent randomness in the world.
- Which is worse, bias or variance? Depends. High-bias models are predictable and safe but uninspired. High-variance models are exciting on training data and dangerous in production. Most interview answers favour caution, which means we control variance first.
- How does this connect to the algorithms I will learn? Every algorithm has a complexity knob (tree depth, k in KNN, regularisation strength). Tuning that knob is moving along the bias-variance seesaw.
8. If This Came In An Interview:
A few questions to be ready for, with one-line answers.
- What is bias? How wrong the model tends to be regardless of what training data we give it. A model too simple to capture the truth has high bias.
- What is variance? How much the model's predictions change when we retrain it on slightly different data. A model that memorises noise has high variance.
- Explain the bias-variance tradeoff in one line. Increasing model complexity lowers bias but raises variance. Decreasing complexity does the opposite. We tune to find the sweet spot.
- How do you detect high bias vs high variance from scores alone? High bias → both train and test scores are low. High variance → train is high but test is low.
- Which algorithms have naturally high bias? High variance? Linear/Logistic Regression have high bias and low variance. Deep Decision Trees and small-K KNN have low bias and high variance. Random Forest reduces variance, gradient boosting reduces bias.
- How would you reduce variance? Get more data, simplify the model, add regularisation, or use an ensemble like Random Forest.
- How would you reduce bias? Use a more flexible model, add features, reduce regularisation, or train longer.
- What is irreducible error? Random noise in the world we cannot remove with any model. Always present in the total error decomposition.
9. Summing It Up:
If we remember one thing from today, it is this: high bias hurts both train and test scores. High variance only hurts test. That one distinction tells us which fix to reach for.
Every model's total error breaks down into bias, variance, and irreducible noise. We rarely shrink bias and variance at the same time, and every hyperparameter we ever tune is just searching for the seesaw's sweet spot.
Coming Up on Day 4
Enough fundamentals. Time to meet our first real algorithm. The one almost every ML textbook starts with, and the one every interviewer expects us to know cold: Linear Regression. We will see how it learns, what its coefficients mean, and why "the line of best fit" is so much more than a school maths trick.
That's all for today. Let's meet up again tomorrow with Day 4.
Thanks for reading.
Cheers!