Day 2: Train-Test Split & The Sin of Overfitting
On Day 1, we said a model "learns" from examples. But how do we actually know if it learned, or if it just memorised?
 Parathan Thiyagalingam
Parathan Thiyagalingam
On Day 1, we said a model "learns" from examples. But how do we actually know if it learned, or if it just memorised? That single question is what train-test split and overfitting exist to answer, and it is one of the most important ideas in all of ML.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Training set: The portion of the data we let the model learn from.
- Test set: The portion we hide from the model and use only at the end to grade it.
- Validation set: A third portion is used while we tune the model, so the test set remains untouched.
- Overfitting: The model memorises training data. It scores high on training but poorly on new data.
- Underfitting: The model is too simple to learn even the training data. It scores poorly on both.
- Generalisation: The ability of a model to perform well on data it has never seen. This is the whole point of ML.
- Cross-validation (CV): Averaging the score over multiple train/test splits to get a more honest number. We will fully cover this on Day 10.
1. A Story Every Student Knows:
Imagine we have a maths exam tomorrow. Two students prepare in very different ways.
- Student A memorises every past paper, including all the answers.
- Student B understands the underlying ideas behind those past papers.
In the practice tests at home, both students scored one hundred per cent. They look identical on paper. Then the real exam comes with completely new questions.
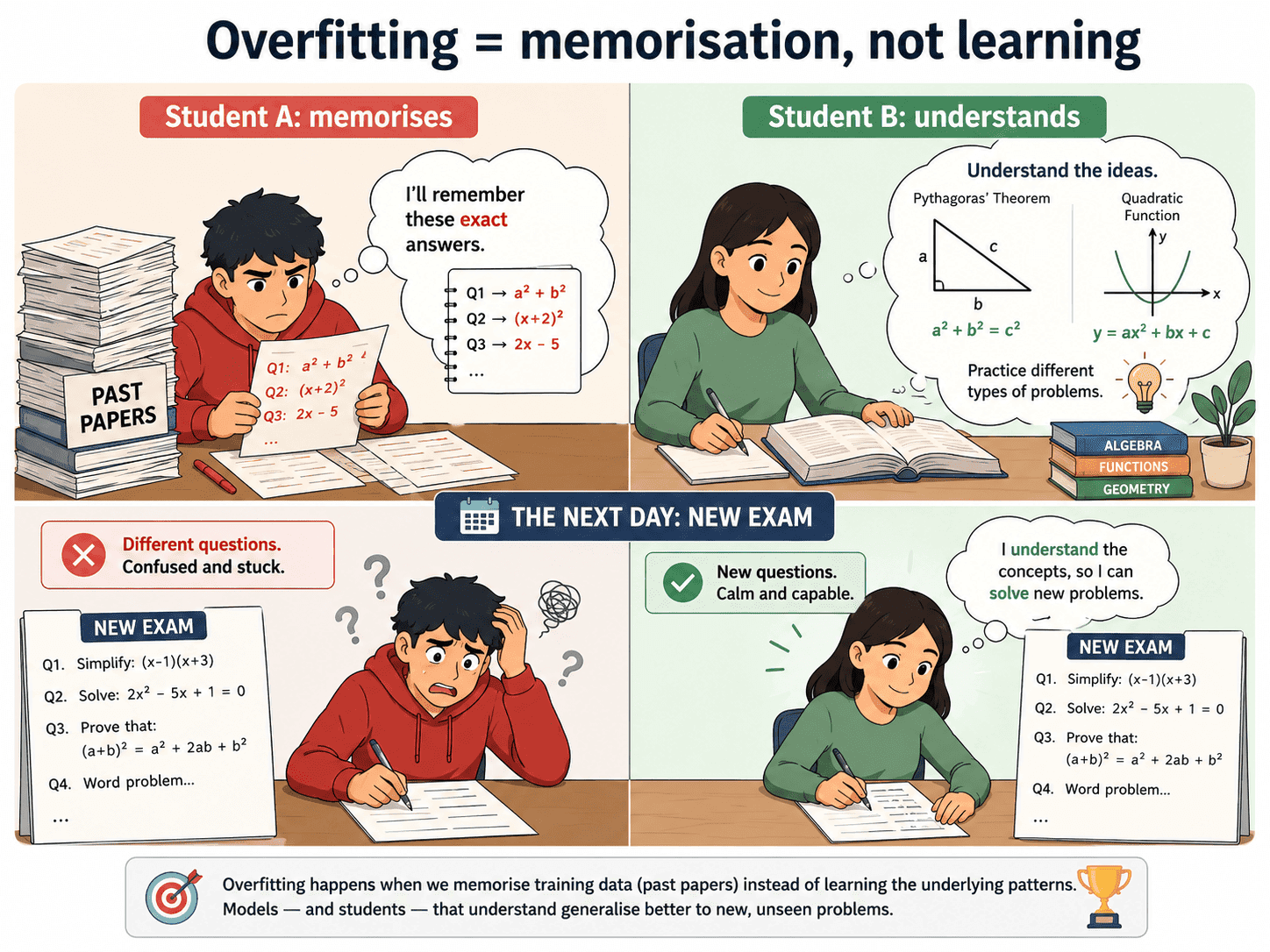
Student A panics. The questions do not match what was memorised. Student B does fine because the same ideas show up, just dressed differently.
This is the entire story of overfitting. Student A is what a badly trained model looks like. The goal of ML is to spot Student A before the real exam, not after.
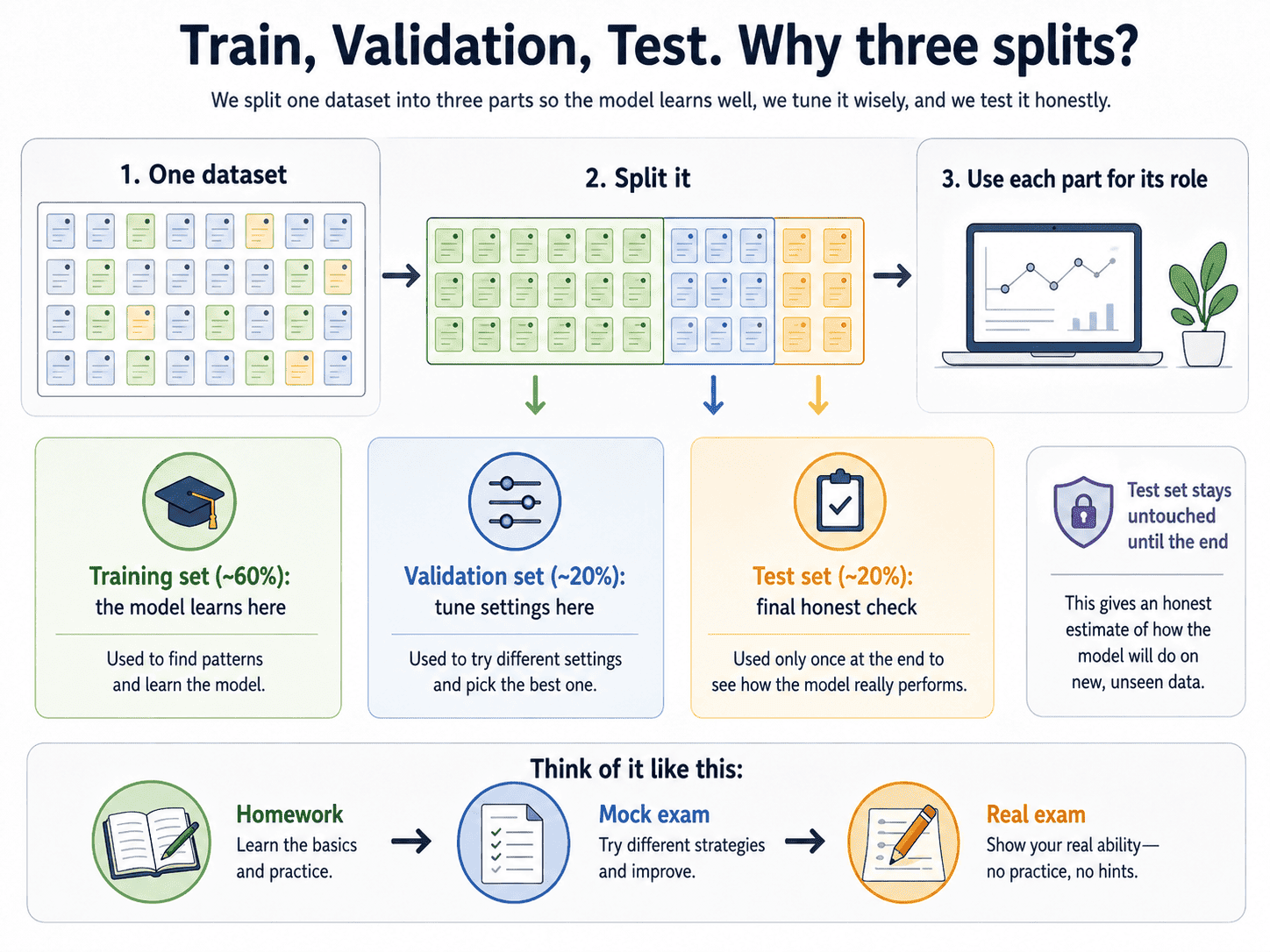
2. The Fix: Holding Some Data Back:
The fix is simple. Do not show the model all of our data during training. Keep a chunk hidden, train on the rest, and then evaluate the hidden chunk. That hidden chunk is the test set.
If a model is memorising, it will perform well on the training set and may perform poorly on the test set, and the gap between them will give it away.
Train set: the examples the model learns from.
Test set: the examples the model is graded on. It must never see these during training.
A common split is 80% training and 20% test. Sometimes 70/30 or 90/10, depending on data size. The exact number matters less than the principle, which is that we always evaluate on data that the model has never seen before.
When we are tuning the model (trying different settings and comparing options), we need a third set called the validation set. The reason is sneaky. Every time we look at the test set and tweak something based on its score, we are leaking information from the test set into our decisions. Eventually, we have over-tuned to the test set itself, and the score becomes a lie.
So the disciplined workflow is:
- Train set (~60%): model learns here.
- Validation set (~20%): we tune knobs here (model choice, hyperparameters – we will learn later).
- Test set (~20%): We touch this exactly once at the very end to report the final score.
Think of it like homework, mock exams, and the real exam. The real exam happens once. No peeking.
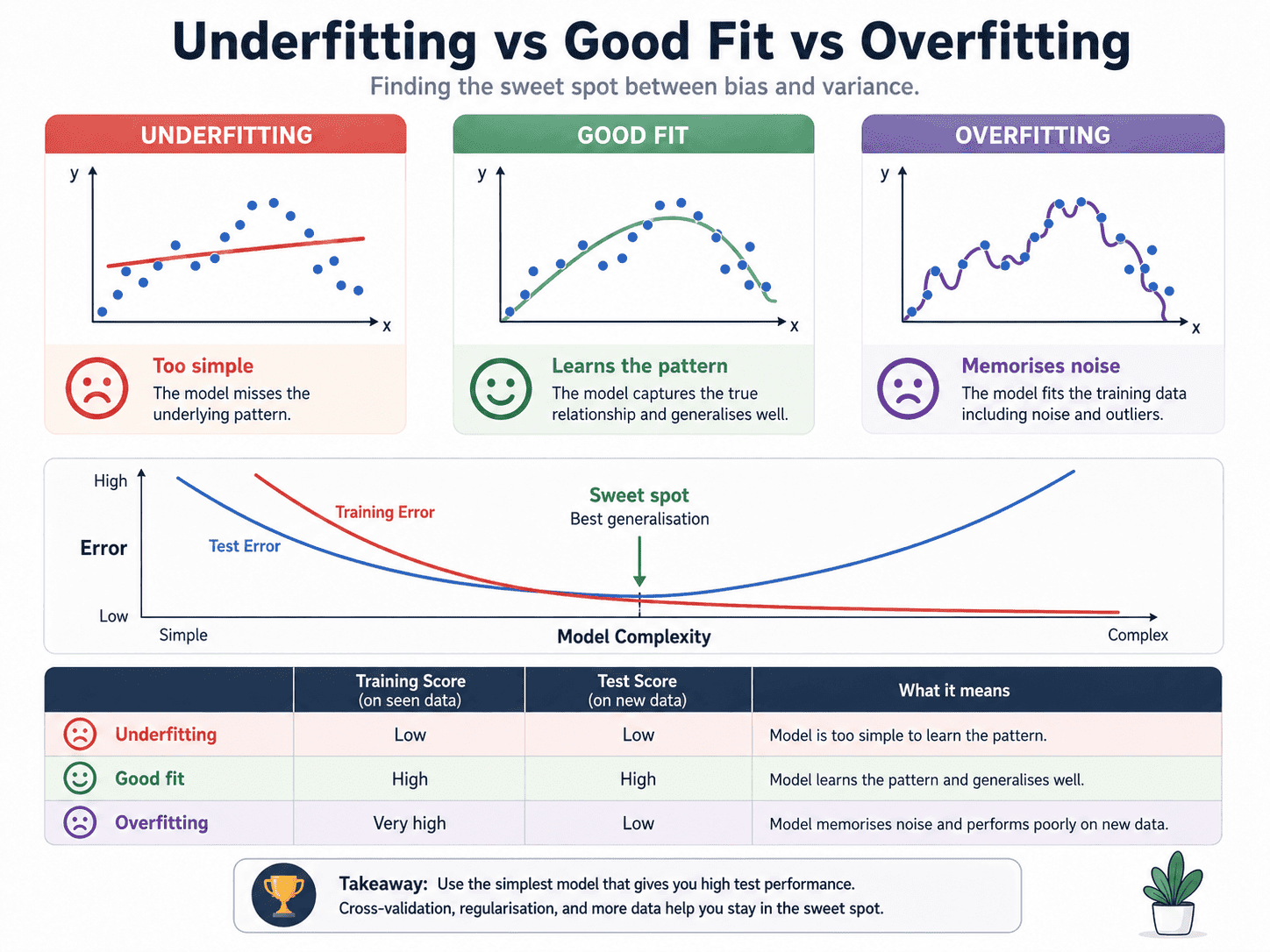
3. What is overfitting?
A model is overfitting when it has memorised the training data rather than learning the underlying pattern. It performs very well on training data but poorly on new data. The tell-tale sign looks like this:
Training accuracy: 99% • Test accuracy: 62%
That gap is the model whispering, "I memorised. I did not learn."
Overfitting tends to happen when:
- The model is too flexible (too many parameters/features, too deep a tree, etc.).
- We have too little data for the model's complexity.
- We trained for too long.
- We have noisy features that the model latched onto as if they were a signal.
4. What is Underfitting?
Underfitting is the opposite problem. The model is too simple to capture the pattern.
Training accuracy: 55% • Test accuracy: 54%
Both are low, and they look similar. The model did not even learn the homework, let alone the exam.
Underfitting usually means:
- The model is too simple (for example, a straight line trying to fit a curvy pattern).
- Important features are missing from our dataset.
- Too much regularisation (we will meet that on Day 9).
A small thought to sit with. If our training and test scores are both bad, the problem is underfitting, and we need a stronger model. But if our training is great and our test is bad, the problem is overfitting, and we need a simpler or better-regularised model: the same low test score, two completely different cures.
5. The Sweet Spot:
Putting it all together, this is the diagnostic table every interviewer expects us to know.

Our job in ML is to land on the third row. The next twenty days are mostly about how to get there.
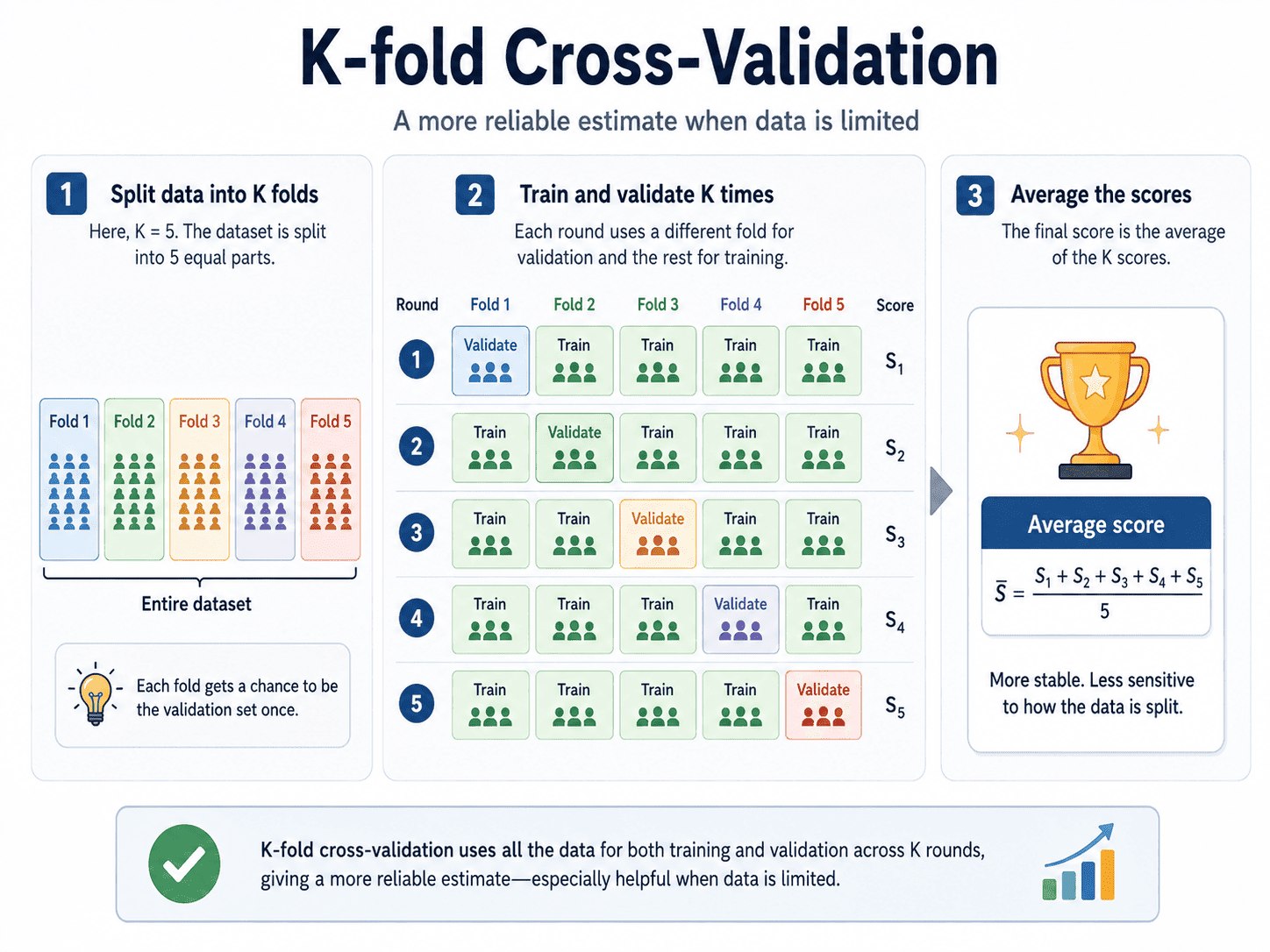
6. A Quick Note on Cross-Validation:
Sometimes, 20% of our data is not enough to evaluate reliably. The score swings depending on which rows happened to land in the test set. The fix is K-fold cross-validation. We split the data into K equal parts, train on K-1 of them, test on the remaining one, then rotate so that every part gets a turn as the test set. We average all K scores at the end.
It is more honest than a single split, especially for smaller datasets. We will dedicate Day 10 to this idea, but the seed is planted today.
7. The Code:
In sklearn, the basic split is one line.
from sklearn.model\_selection import train\_test\_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
Three small things to know:
- test_size=0.2 means 20% of the data is used for the test set.
- random_state=42 makes the split reproducible, so we get the same result every run.
- For classification, we should add stratify=y to ensure that both the training and test sets keep the same class proportions. This matters a lot for imbalanced data, which we will see on Day 11.
8. A Few Common Confusions Cleared:
Before we close, here are some questions beginners often have.
- Why must the test set be untouched until the end? Because every glance is a tiny act of cheating. If we tweak the model based on test scores, we have turned the test set into a validation set, and our final score becomes unreliable.
- Is 80/20 a magic number? No. With a small dataset, use cross-validation. With a huge dataset (millions of rows), even 99/1 is fine because 1% is still plenty of test data.
- Why use random_state? Without it, we get a different split every run, so we cannot reproduce results or fairly compare experiments.
- What is a "holdout set"? Just another name for the test set we keep aside.
- Does overfitting only happen in complex models? Mostly, but not only. A simple model trained on tiny, noisy data can still overfit. Data size matters as much as model size.
9. If This Came In An Interview:
A few questions to be ready for, with one-line answers.
- Why do we split the data into training and test sets?: To measure how well the model generalises to data it has not seen. Training scores alone can hide memorisation.
- Why do we need a validation set as well?: Because every time we tweak the model based on the test score, we leak information from the test into our decisions. Validation is for tuning; a test is for the final verdict.
- What is overfitting?: When the model has memorised the training data and performs well on training, but poorly on new data. The tell-tale sign is a big gap between training and test scores.
- What is underfitting?: When the model is too simple to learn the pattern, both training and test scores are low.
- What is generalisation?: Doing well on data the model has never seen. It is the whole point of ML.
- Why use stratify=y in classification?: To keep class proportions equal across the train and test sets. Especially important on imbalanced data, where a non-stratified split can swing the score by a lot.
- How big should the test set be?: Usually 20% with small/medium data, less with very large data (1% is fine on millions of rows). The principle matters more than the exact number.
10. Summing It Up:
If we remember one thing from today, it is this: a model that scores 100% on training is almost never a good thing. It is memorisation hiding behind a confident number.
The whole point of ML is generalisation, which means doing well on data the model has never seen. The train-test split is how we measure it; overfitting and underfitting are how we fail at it, and almost every technique we learn from here on is just a tool to balance the two.
Coming Up on Day 3
Today, we saw that overfitting and underfitting are the two failure modes of ML. Tomorrow, we look at the deeper trade-off that explains every modelling decision we will ever make: the bias-variance trade-off. If we understand this one idea, we understand around 70% of model selection.
That's all for today. Let's meet up again tomorrow with Day 3.
Thanks for reading.
Cheers!