Day 22: Data Leakage, ML Workflow & Interview Cheat Sheet
Day 22: Data Leakage, ML Workflow & Interview Cheat Sheet
 Parathan Thiyagalingam
Parathan Thiyagalingam
Twenty-one days, fifteen algorithms, six fundamentals. Today we tie everything together: the end-to-end workflow we would actually use in a job, the silent killer that breaks every other beginner pipeline, and the interview cheat sheet covering every "why" question we have touched.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Data leakage: Information from outside the training data sneaks in. Great experiment scores, terrible production performance.
- Target leakage: A feature secretly contains information about the target.
- Time leakage: Accidentally using future data to predict the past.
- ML pipeline: A codified sequence of preprocessing plus a model, so train and test get identical treatment.
- Data drift / Concept drift: Features (or the feature-target relationship) shift after deployment.
- MLOps: The engineering practice of deploying, monitoring, and maintaining ML models in production.
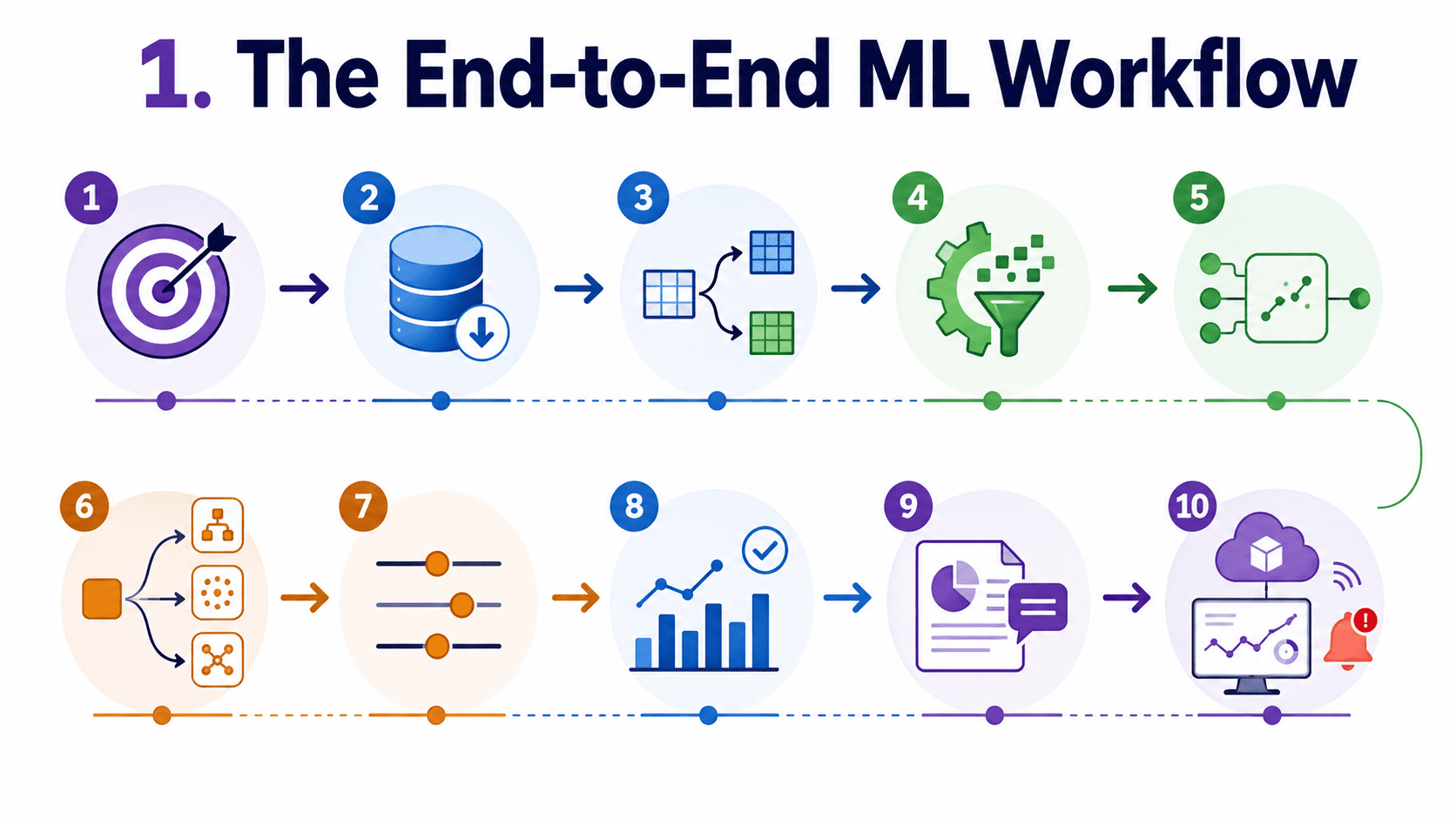
1. The End-to-End ML Workflow:
Real ML projects follow a predictable shape. If an interviewer asks "walk me through how you would build an ML model," our answer should sound like the steps below.
Step 1: Define the problem.
Before any code, ask the basics. What are we predicting (the target)? Why does it matter (the business goal)? How will success be measured (the metric, see (Day 6 Evaluation Metrics — How Do We Know a Model is Good)?
What data exists?
The biggest cause of failed ML projects is not bad models, it is solving the wrong problem.
Step 2: Get the data.
Gather, join, clean. Inspect distributions, missing values, target balance (Day 11 Class Imbalance — Why Accuracy Lies), and feature types.
df.describe()
df.isnull().sum()
df['target'].value_counts(normalize=True)
Step 3: Split right away.
Split train and test before doing anything else.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
Use stratify for classification. Use a time-based split for time series. If we peek at test data even once, we have poisoned the experiment.
Step 4: Feature engineering and preprocessing.
Within the training set. Handle missing values, encode categoricals, scale features for distance-based and gradient-based models, and engineer new features ([[Day 8 Feature Engineering & Preprocessing|Day 8]]). Always use a sklearn Pipeline so the same steps apply identically to train and test.
Step 5: Baseline model.
Start dumb. Try Logistic Regression or a Decision Stump. Record the score. Every fancy model is judged relative to this baseline.
Step 6: Iterate with better models.
Move up the ladder.
- Linear and Logistic Regression (Day 4 Linear Regression — Fitting the Best Line and Day 5 Logistic Regression — When the Answer is Yes or No).
- Decision Trees and Random Forest (Day 14 Decision Trees — Twenty Questions Automated and Day 15 Random Forest — Wisdom of the Crowd).
- Gradient Boosting and XGBoost (Day 16 Gradient Boosting & XGBoost — Learning from Mistakes).
- SVM or KNN if relevant (Day 17 Support Vector Machines — Drawing the Widest Lane and Day 12 K-Nearest Neighbors — Tell Me Who Your Friends Are).
Run cross-validation (Day 10 Cross-Validation & Hyperparameter Tuning) on each. Compare honestly.
Step 7: Tune hyperparameters.
Once we have picked a model, tune it with Random Search or Grid Search inside CV.
Step 8: Evaluate on the test set (once).
Only now. The honest final score.
Step 9: Interpret and communicate.
Feature importance plots, confusion matrix, real-world impact ("we would catch 80% of fraud at a 5% false alarm rate").
Step 10: Deploy and monitor.
The model goes into production. We monitor for:
- Data drift: features start looking different from training.
- Concept drift: the relationship between features and target shifts over time.
- Performance decay: score drops over time.
These last steps blur into MLOps, which is outside the scope of this series. Just be aware they exist.
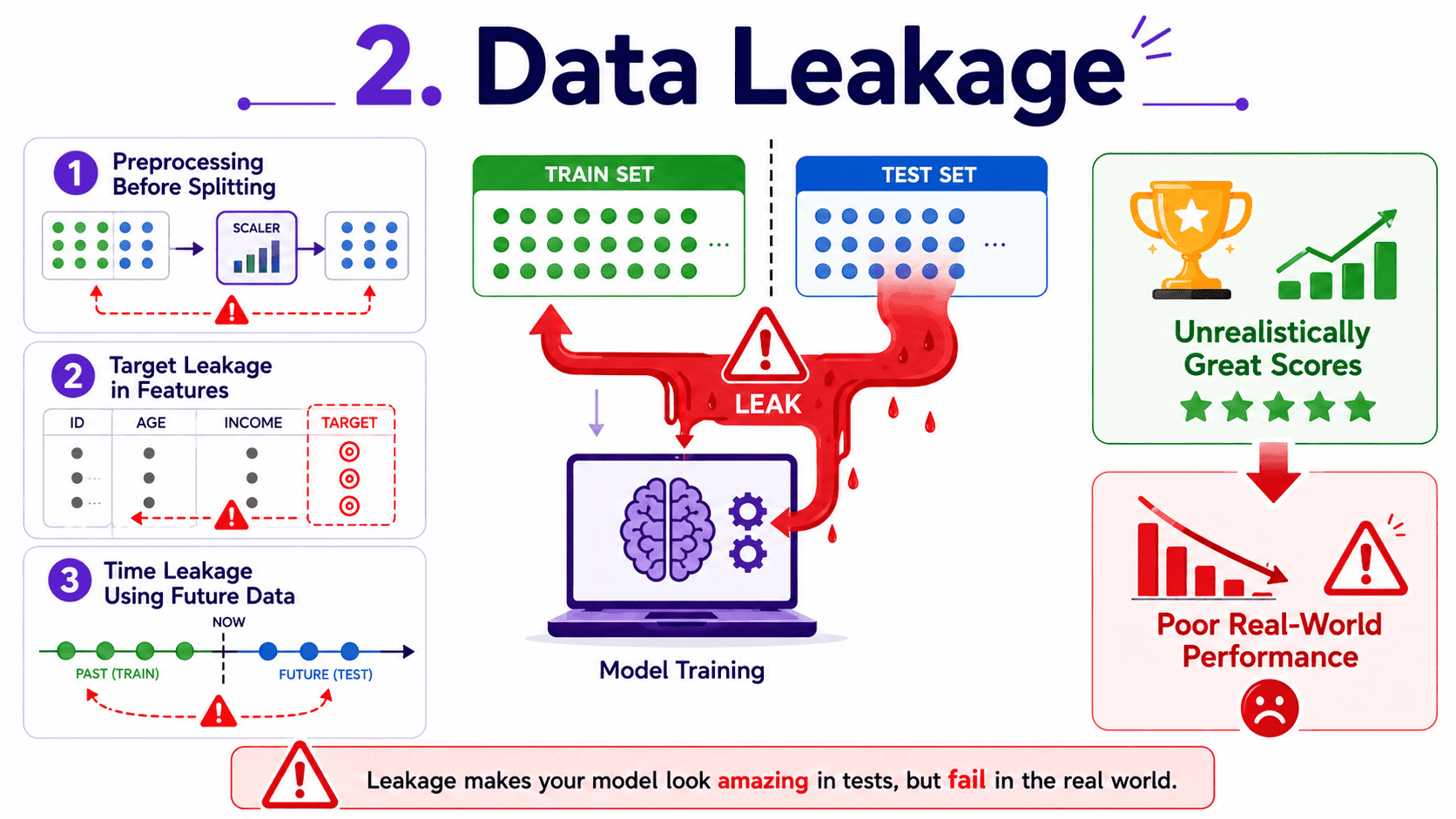
2. Data Leakage:
Data leakage is when information from outside the training set sneaks into the training process. The result is dazzling training and test scores in our experiments, then total failure in production. It is the number-one reason beginners' models look great in notebooks and disaster in real life.
Three common leakage patterns.
Preprocessing before splitting.
# WRONG
scaler = StandardScaler().fit(X) # uses ALL data
X_scaled = scaler.transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y)
The scaler used statistics from the test set. Our model has subtly seen test data. The fix is to always split first, fit preprocessing on train only, transform test using train's statistics. Or use a sklearn Pipeline, which handles this for us automatically.
# RIGHT
X_train, X_test, y_train, y_test = train_test_split(X, y)
scaler = StandardScaler().fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
Target leakage in features. Features that secretly contain information about the target.
- Predicting churn, but one of our features is
cancellation_date(only filled for churners). - Predicting fraud, but a feature is
was_flagged_by_other_system. - Predicting hospital readmission with
total_hospital_visits_including_this_one.
Easy to miss. Usually betrayed by suspiciously high feature importance. The fix: for every feature, ask "would this be known at the moment we make the prediction?" If no, drop it.
Time leakage. Using future to predict the past in time series.
# WRONG for time series
train_test_split(X, y, test_size=0.2, random_state=42) # randomly mixes time periods
Our "test" might be from January, our "train" from June. That is not how production works. Fix: use TimeSeriesSplit or split chronologically.
The test for leakage. If our model's CV score is suspiciously high (for example 99%) on a hard problem, we suspect leakage first. We check:
- Are any features computed using the target?
- Is preprocessing fit on the full dataset?
- Are temporal or group structures respected?
- Has the test set been touched during training?
Leakage is everywhere. Senior ML engineers are paranoid about it for good reason.
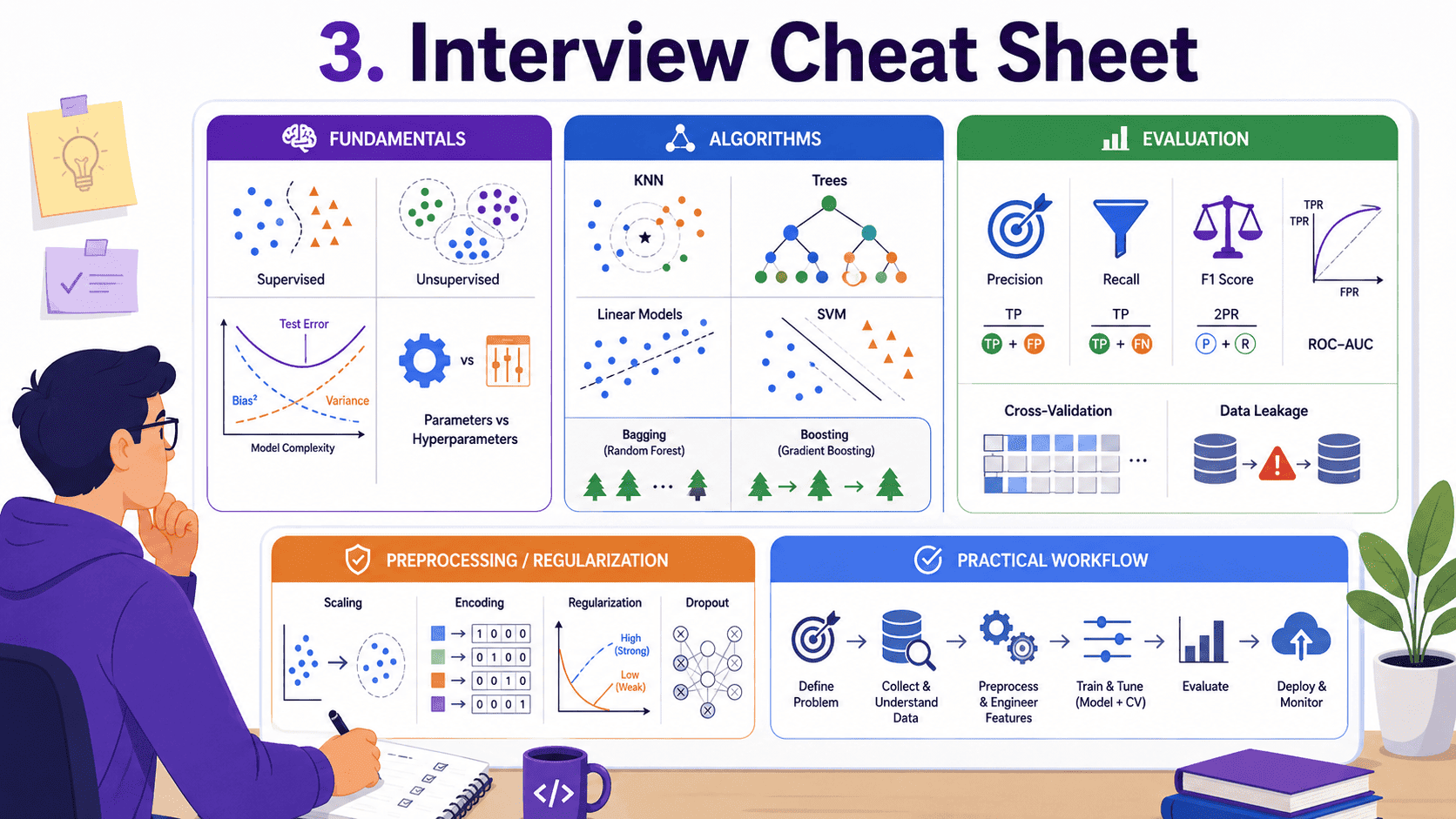
3. Interview Cheat Sheet:
Every concept from Days 1 to 21, distilled into the answers we will be asked.
Fundamentals.
- What is the difference between supervised and unsupervised learning? Supervised has labels (y) and we learn to predict y from x. Unsupervised has no labels, and we find structure (clusters, components).
- What is overfitting vs underfitting? Overfit means high train score, low test score (memorised). Underfit means both are low (too simple).
- Bias-variance tradeoff in one line? Bias is being wrong on average. Variance is being inconsistent. Lowering one usually raises the other.
- What is the difference between a parameter and a hyperparameter? Parameters are learned by the algorithm (β coefficients, tree splits). Hyperparameters are set by us before training (learning rate, max_depth).
- Generative vs discriminative model? Generative models P(features, class) (Naive Bayes). Discriminative models P(class | features) directly (Logistic Regression, SVM).
- Parametric vs non-parametric? Parametric = fixed number of parameters regardless of data size (Linear Regression). Non-parametric = grows with data (KNN, Decision Tree).
Algorithms.
- Why is Logistic Regression a linear model? Because the decision boundary it draws between classes is linear in the features. The sigmoid only transforms the output to a probability.
- Why does Logistic Regression use log loss and not MSE? Because MSE with sigmoid gives a non-convex loss surface with flat regions. Log loss is convex and trains cleanly.
- Why is Naive Bayes called naive? Because it assumes all features are conditionally independent given the class. Usually wrong, but the algorithm still works well.
- Why does KNN need feature scaling but Decision Trees do not? KNN uses distance, so large-magnitude features dominate. Decision Trees use per-feature thresholds, so scale does not matter.
- Bagging vs Boosting? Bagging trains models in parallel on different random subsets and averages them (Random Forest, reduces variance). Boosting trains models sequentially, each correcting the previous mistakes (XGBoost, reduces bias).
- When would you use Random Forest over XGBoost? RF when we want easy and robust with minimal tuning. XGBoost when we want top performance and have time to tune.
- What is the kernel trick in SVM? A way to compute as if we projected data into a higher-dimensional space, where a non-linear problem becomes linear, without actually projecting it.
- How does K-Means work? 1. Pick K centroids randomly. 2. Assign each point to its nearest centroid. 3. Move centroid to mean of its points. 4. Repeat until stable.
- How do you choose K in K-Means? Elbow method (plot WCSS vs K). Silhouette score. Business constraints.
- K-Means vs DBSCAN? K-Means needs K upfront and produces spherical clusters with no noise. DBSCAN is density-based, handles any cluster shape, finds K automatically, and identifies outliers.
- What is PCA? A linear dimensionality reduction that finds directions of maximum variance and projects data onto the top K. Used for visualisation, speed, noise reduction, and tackling multicollinearity.
Evaluation.
- Why is accuracy a bad metric on imbalanced data? Because saying "majority class" to everything gives high accuracy without learning anything. Use precision, recall, F1, or PR-AUC.
- Precision vs recall? Precision asks "when I say yes, am I right?". Recall asks "of all real yeses, how many did I catch?".
- What is F1 and when do you use it? Harmonic mean of precision and recall. A good single number for imbalanced classification when both matter.
- What is ROC-AUC? Area under the curve plotting True Positive Rate vs False Positive Rate as the threshold varies. Threshold-independent measure of how well a model ranks positives above negatives. 0.5 is random, 1.0 is perfect.
- R² in plain English? Fraction of variance in y explained by the model. 1.0 is perfect, 0 is no better than always predicting the mean.
Preprocessing and regularisation.
- Which models need scaling? Which do not? Need: Linear and Logistic Regression, KNN, SVM, K-Means, PCA. Do not: Decision Trees, Random Forest, Gradient Boosting, Naive Bayes.
- L1 vs L2 regularisation? L1 (Lasso): sum of absolute values, zeros out useless coefficients (feature selection). L2 (Ridge): sum of squares, shrinks all coefficients but keeps them.
- How would you handle class imbalance? 1. Use proper metrics (F1, PR-AUC). 2.
class_weight='balanced'. 3. Threshold tuning. 4. SMOTE or under/oversampling. 5. Try tree-based models. - What is cross-validation and why use it? Repeatedly splitting train into folds for evaluation, then averaging across folds. More reliable than a single hold-out. Gives mean plus standard deviation of expected performance.
Practical / Workflow.
- What is data leakage? Information from outside training data sneaking into training. Causes great experiment scores and terrible production performance.
- Why fit preprocessing on train only? Otherwise the test set's statistics leak into training, giving optimistic results.
- Gradient Descent, how does it work? Start with random parameters. Compute the gradient of the loss. Take a small step downhill (negative gradient times learning rate). Repeat until loss stops dropping.
- What happens if the learning rate is too high? Too low? Too high: oscillates or diverges, never settles. Too low: training crawls and may never reach the minimum.
4. Final Words:
Twenty-two days. From "what is ML?" to interview-ready. To go from here to a job offer, three more things matter.
- Build two or three end-to-end projects. Kaggle, our own data, anything. Theory without practice does not pass coding rounds.
- Talk about our projects fluently. Practice explaining what we built, why, what worked, and what did not.
- Stay curious. ML is moving fast. The fundamentals here are stable, but the frontier (deep learning, LLMs) keeps changing.
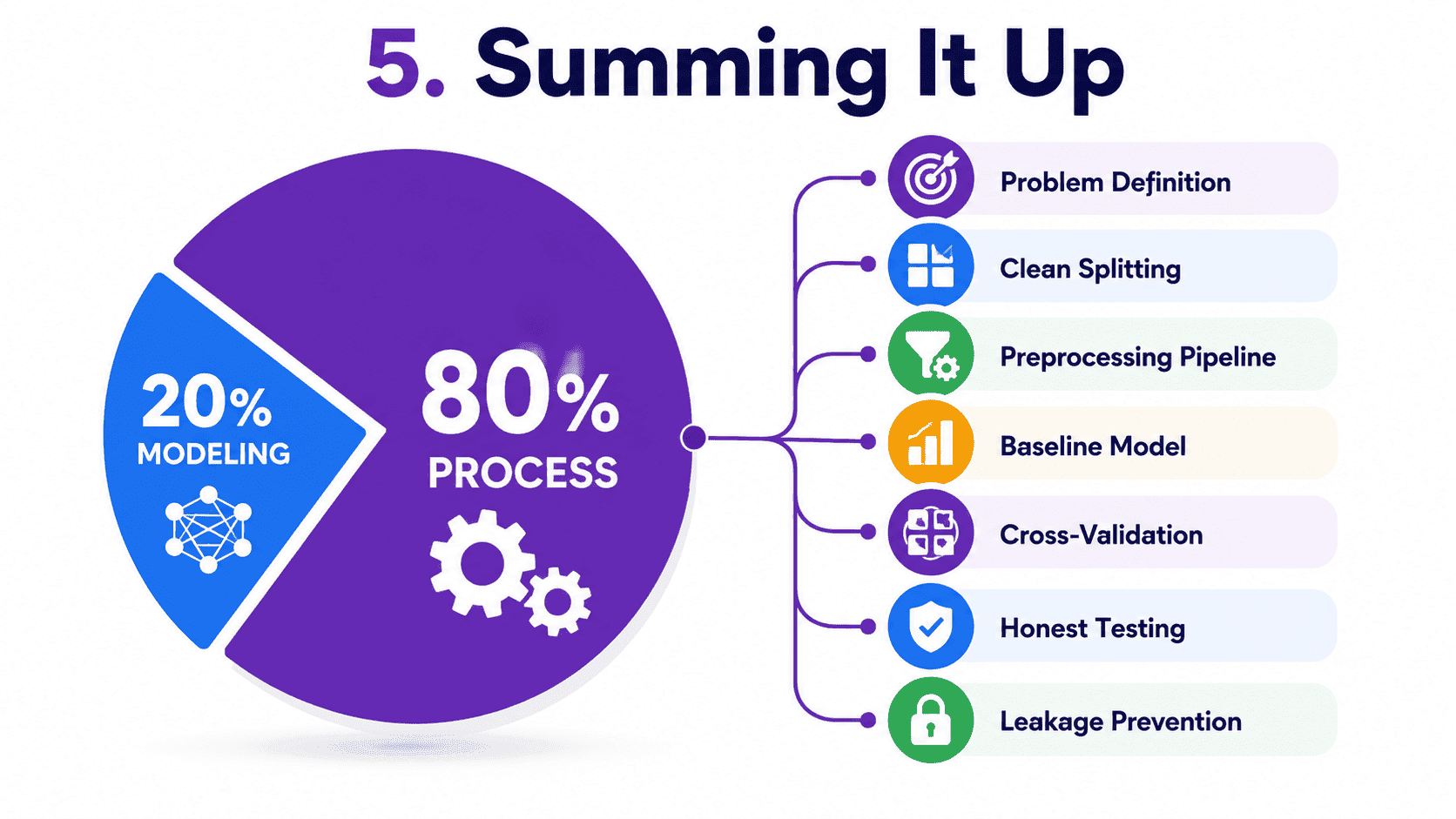
5. Summing It Up:
If we remember one thing from today, it is this: a working ML project is roughly 20% modelling and 80% process. Define the problem, split data first, build preprocessing into a pipeline, baseline before fancy models, validate honestly with CV, evaluate on test exactly once, and obsess over data leakage. The interview "why" questions are predictable. If we can explain each algorithm's intuition, tradeoffs, and the data it needs, we are ready.
The End
This is the final day of the series. We now have the conceptual foundation to understand any classical ML algorithm an interviewer might mention, diagnose model problems (bias vs variance, leakage, imbalance), pick the right metric, preprocessing, and algorithm, and talk fluently through the ML workflow.
Beyond classical ML, the next horizons are deep learning (neural networks, CNNs for images, transformers for sequences), MLOps (pipelines, deployment, monitoring, model versioning), and specialised domains (NLP, computer vision, time series, recommender systems). But those are for another series.
For now, go and build something.
That's all for the ML series. It has been a wonderful journey writing these notes, and I hope they help anyone reading along to feel more confident about ML.
Thanks for reading.
Cheers!