Day 2: Embeddings & Vector Databases — How Computers Understand Meaning
This blog post is a daily learning summary of my 40 Day RAG class from Syed Jaffer of Parotta Salna.Why Keyword Search Isn't EnoughYour knowledge base says:"My...
 Parathan Thiyagalingam
Parathan Thiyagalingam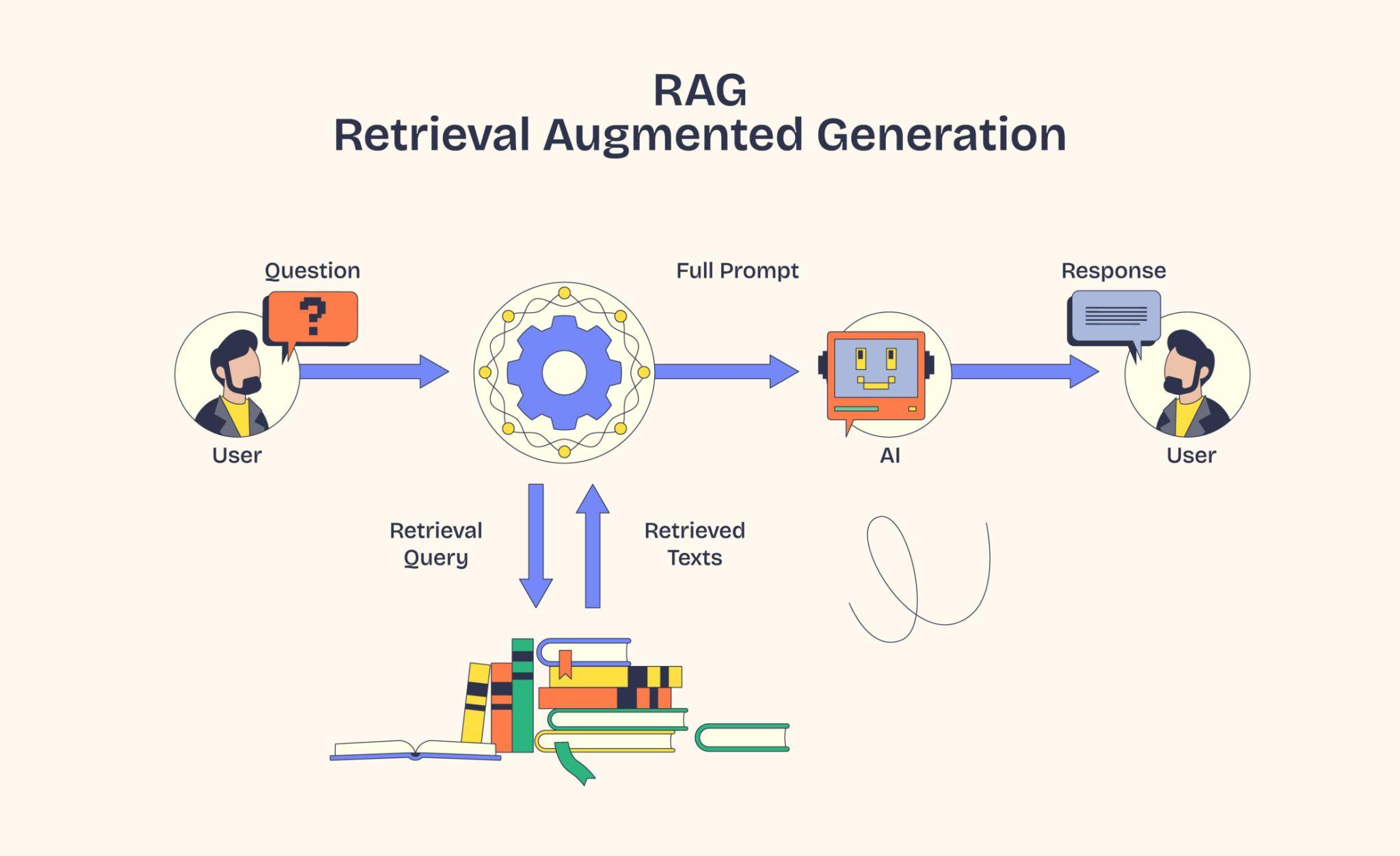
Day 1 ended with a teaser. The model "embeds" text into numbers and stores them in a "vector database". Today, we make that concrete. What an embedding really is, how numbers can capture meaning, and why a vector database instead of plain SQL.
This blog post is a daily learning summary of my 40-day RAG class from Syed Jaffer of Parotta Salna.
Terms Used Today
- Embedding: A list of numbers (a vector) that captures the meaning of a piece of text.
- Embedding model: A pre-trained model that takes text in and gives the embedding numbers out.
- Cosine similarity: A score for how close two embeddings are in direction. Higher means more similar in meaning.
- Vector database: A database built for one job: given a query embedding, find the closest stored embeddings fast.
- ANN (Approximate Nearest Neighbour): The indexing trick that makes vector search fast at scale by skipping most obviously irrelevant vectors.
1. Why Keyword Search Isn't Enough:
Suppose our knowledge base says:
"My dog brings me so much joy."
And the user asks:
"How does owning a pet improve happiness?"
Zero shared keywords. A regular Ctrl+F-style search would miss it completely, even though the document clearly answers the question.
We need something that understands meaning, not spelling. That is what embeddings do.
2. What is an embedding?
Imagine a giant map where every word, sentence, or paragraph has a location based on its meaning.
- "Dog" and "puppy" sit right next to each other.
- "Dog" and "wolf" are nearby.
- "Dog" and "spaceship" are on opposite ends.
An embedding is just the coordinates of a piece of text on this meaning map.
The twist. Instead of 2D (latitude, longitude), embeddings live in hundreds or thousands of dimensions. That is how they capture so much subtlety.
Embeddings even let us do maths on meaning:
king − man + woman ≈ queen
That is how rich the encoding is.
3. How We Create Embeddings:
We do not train our own. We use a pre-trained embedding model.
Popular ones:
- OpenAI's
text-embedding-3 - Cohere Embed
- The free
sentence-transformersfamily from Hugging Face
Feed text in, get a list of numbers out. That is the whole interface.
There is one rule we cannot break.
Use the same embedding model for documents AND queries.
Different models give different coordinate systems. Mixing them is like asking for directions using Mars GPS on an Earth map. Nothing matches.
4. Measuring Closeness with Cosine Similarity:
Once everything is on the meaning map, we need a way to ask, "How close are these two things?"
The most common answer is cosine similarity.
Picture each embedding as an arrow shooting out from the centre. Cosine similarity asks how much these two arrows point in the same direction.
- 1.0 means the same direction (identical meaning).
- 0.0 means perpendicular (unrelated).
- −1.0 means opposite (rare in practice).
It cares about direction, not length, which is why it works even when texts are different sizes. We will go deeper into cosine on Day 6.
5. What is a Vector Database?
So we have embedded a million chunks. Now we need to store them and quickly find the ones closest to a query embedding.
Could we dump them into Postgres and brute-force compare every row? Sure, until we have 10 million chunks and queries take forever.
A vector database is purpose-built for one job:
"Given this query vector, find the top-k closest vectors fast, even at scale."
It pulls this off with an indexing trick called 'Approximate Nearest Neighbour' (ANN) search, which narrows the search space dramatically with a tiny accuracy tradeoff.
Popular vector databases:
- Chroma: local prototyping, beginner-friendly.
- FAISS: high-performance library from Meta.
- Pinecone: fully managed cloud service.
- Weaviate / Qdrant: open-source, production-ready.
- pgvector: adds vectors to your existing Postgres.
Start with Chroma or FAISS. They run on a laptop; no signup is needed.
6. The Build Phase in Pictures:
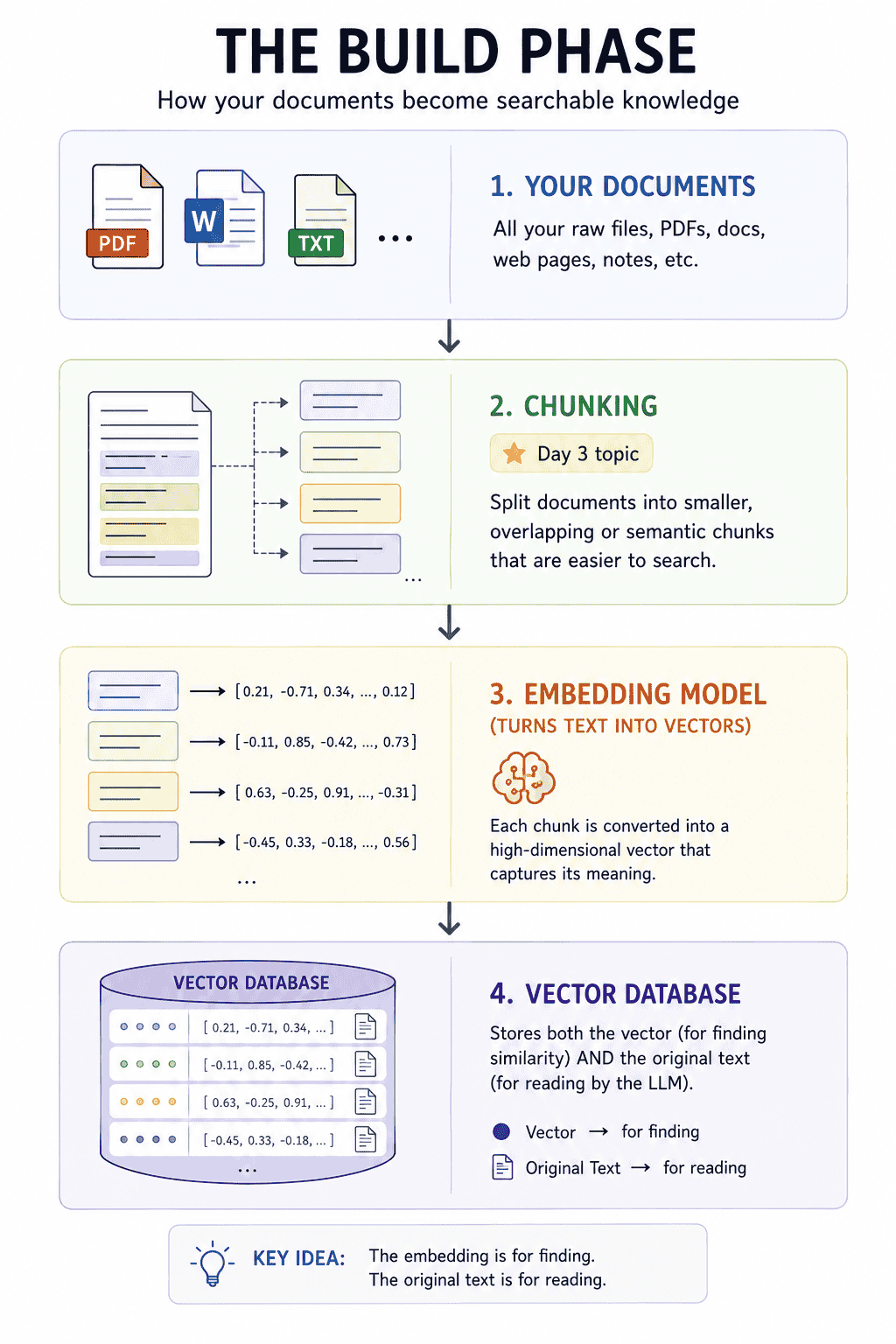
The original text is stored alongside the embedding because the LLM cannot read embeddings, only actual text. The embedding is for finding; the text is for reading.
7. If This Came In An Interview:
- What is an embedding, in plain English? A list of numbers representing the meaning of text, like coordinates on a "meaning map" where similar meanings sit close together.
- Why use embeddings instead of keyword search? They capture meaning, not just exact words. So "my dog brings me joy" matches "owning a pet improves happiness", even without any shared words.
- What is the most important rule when using embeddings? Use the same model for documents and queries. Different models live in different coordinate systems.
- What is cosine similarity? A score from −1 to 1 for how aligned two embedding arrows are. Higher means more similar in meaning.
- Why a vector database instead of plain SQL? Vector DBs use ANN indexing for fast nearest-neighbour search at scale. Plain SQL would brute-force compare every row.
8. Summing It Up:
If we remember one thing from today, it is this: embeddings turn text into coordinates on a "meaning map", and vector databases find the closest coordinates fast. Together, they let computers search by meaning rather than by matching keywords.
Coming Up on Day 3
We have talked about embedding "chunks", but what is a chunk, and how do we split documents in the first place? Tomorrow we tackle the unsexy decision that quietly determines whether a RAG system works at all. Bad chunking = bad RAG. Period.
That's all for today. Let's meet up again tomorrow with Day 3.
Thanks for reading.
Cheers!
-1778189655348.png)