Day 1: What is Machine Learning — The Three Flavors
Day 01 of Machine Learning Fundamentals
 Parathan Thiyagalingam
Parathan Thiyagalingam
After spending the last few weeks documenting my RAG self-study journey (you can find those posts under the RAG section), I have decided to dive into the fundamentals of machine learning as well. The plan is simple. I want to understand the building blocks of ML, learn each algorithm in a beginner-friendly way, and be confident enough to discuss them in an interview or at work without feeling lost.
This series will run for twenty-two days, covering the types of machine learning, the supervised algorithms, the unsupervised ones, and the practical things like preprocessing, regularisation, and evaluation that real-world projects depend on. We will skip neural networks for now and focus on classical ML.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Machine Learning (ML): A way of programming where the computer learns the rules from examples instead of being given the rules by us.
- Algorithm: The recipe for learning. For example, "Fit a line through these points."
- Model: The result we get after running that recipe on actual data. For example, the specific line y = 2x + 3, which we ended up with.
- Feature: An input we feed the model, often denoted by X (also called the predictor, independent variable, or column).
- Target: The answer we are trying to predict, often written as y (also called label, dependent variable, 'output', or 'response').
- Prediction (ŷ, "y-hat"): The model's output for a given input. We compare ŷ to the true y to compute the error.
- Data point: A single example or row in our dataset (also called a sample, instance, or observation).
- Label: The correct answer attached to each example in supervised learning (essentially, the known target during training).
1. From Rules to Examples:
Imagine we want to build a spam filter for our inbox. The traditional way is to sit down and write a long list of rules.
- "If the email contains 'free Viagra', mark it as spam."
- "If it has more than five exclamation marks, mark it as spam."
- "If it claims to be from Nigerian royalty, mark it as spam."
We would be writing rules forever. And every time the spammers change their tactics, we would have to start over.
Machine learning takes a different route. Instead of writing the rules, we show the computer thousands of emails, labelled as spam or not-spam, and let it figure out the pattern on its own. This is what we mean when we say a model "learns".
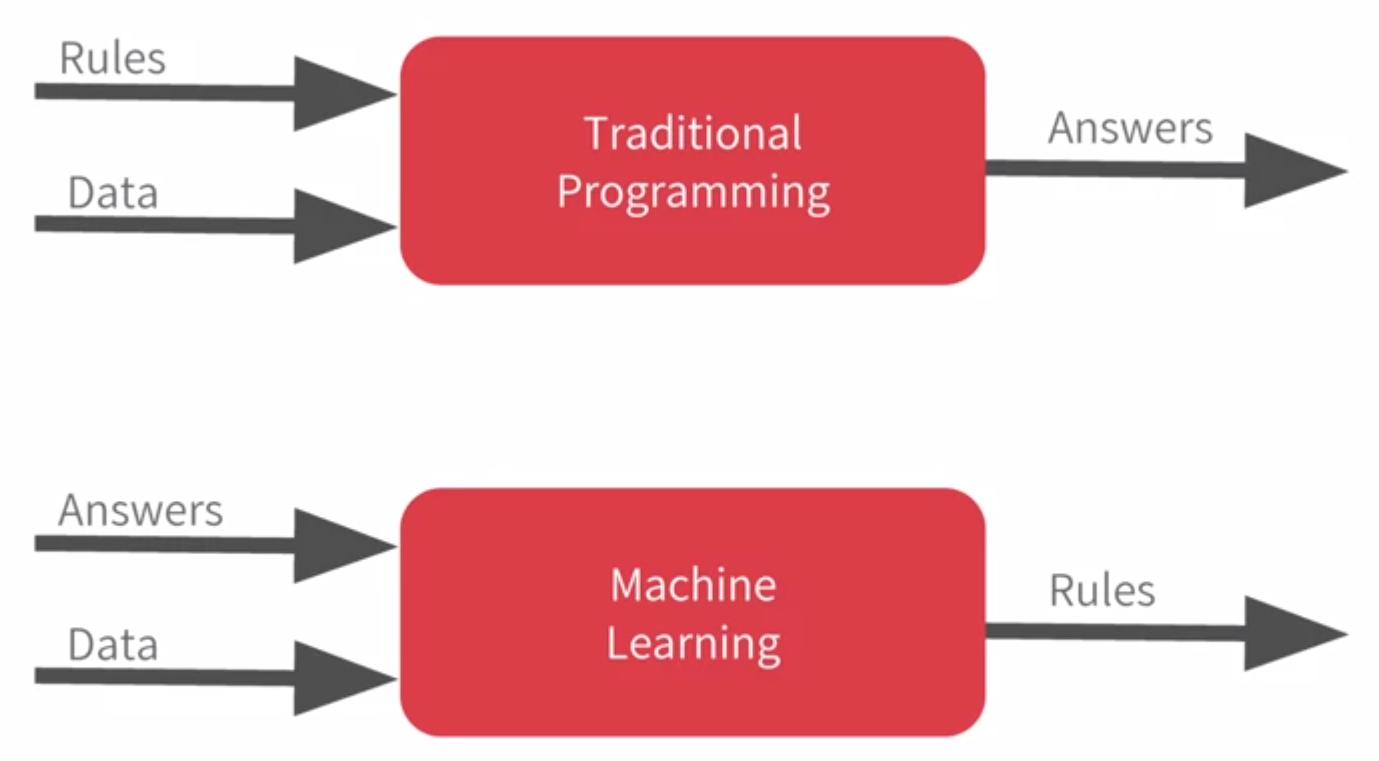
Traditional programming: rules + data → answers
Machine learning: data + answers → rules
That flip is the whole idea behind ML, and once we see it, everything else in this series will sit on top of it.
2. What "Learning" Actually Means:
Learning, in plain English, means reducing error. At its core, a model takes an input (X), makes a prediction (often denoted by 'ŷ', or 'y-hat'), and we compare that prediction to the true value (y). The gap between them is the error. The bigger the gap, the bigger the adjustment. Over many rounds, those adjustments add up, and the model gets better.
A tiny concrete example. Say we have three data points.
Data: (1, 2), (2, 4), (3, 6)
The model starts with random guesses, sees how far off they are, and after a few rounds, it lands on the rule:
Learned model: y = 2x
Three data points in, one rule out. That is the whole loop, just scaled up to thousands or millions of points.
In any ML project, three ingredients always show up.
- Data: The examples we have collected, such as emails, photos, or sales numbers.
- A goal: What we want the model to do, such as predict spam, predict a house price, or group similar customers.
- A learning algorithm: The procedure that finds the pattern by reducing error step by step.
And one more thing worth planting now — the real goal of all this is not to do well on the data the model has seen. The real goal is to do well on data that the model has never seen. That property is called generalisation, and we will devote a full day to it on Day 2. For now, hold that thought.
Different goals lead to different flavours of machine learning, which brings us to the next section.
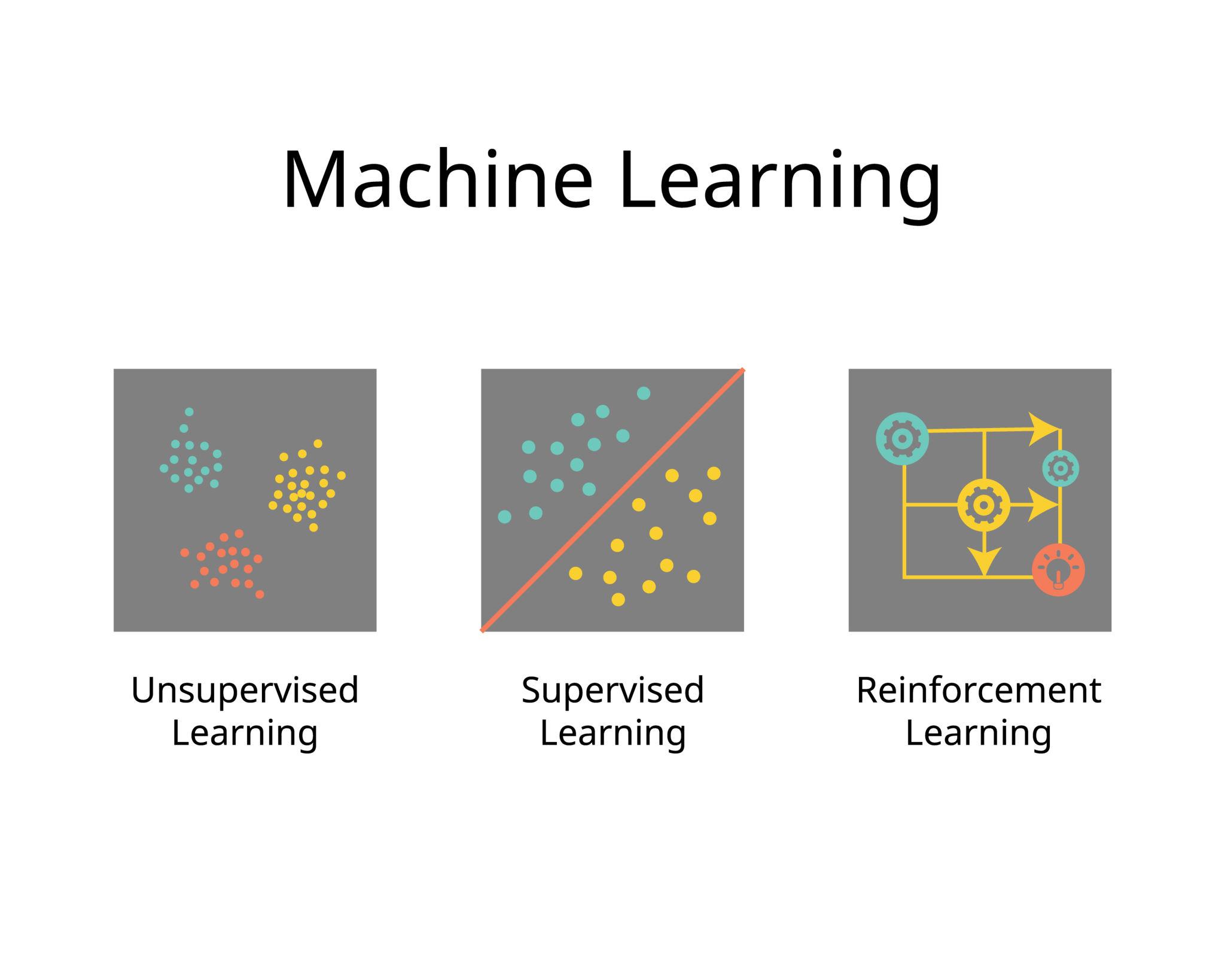
3. The Three Flavors of Machine Learning:
Most ML problems fall into one of three categories. We will spend the next twenty-one days mostly on the first two.
Supervised Learning: Here, we have both the data and the correct answers. We show the model that "this input gave that answer, this input gave that answer", and after enough examples, the model learns to predict the answer for new inputs.
For example,
- An email plus its label (spam or not spam) gives us a spam filter.
- A house plus its price gives us a price predictor.
- A tumour scan, along with its diagnosis, gives us a medical classifier.
This is the most common flavor in industry, and it is also the one most asked about in interviews. Around eighty per cent of this series will live here.
Recall from our terms – the inputs (the email's words, the house's size, the scan's pixels) are the features (X), and the answer we want (spam or not, the price, the diagnosis) is the target (y). In supervised learning, our job is to learn a mapping from X to Y, using examples where we know both.
Within supervised learning, there are two subtypes worth naming now.
- Regression: Predicting a number, such as a house price or tomorrow's temperature.
- Classification: Predicting a category, such as spam or not-spam, or dog or cat.
Unsupervised Learning: Here, we have data but no labels. The model has to find its own structure.
For example,
- "Here are ten thousand customers; group similar ones together." This gives us clustering for marketing.
- "Here are a thousand features per row; squash them into ten without losing meaning." This gives us dimensionality reduction.
- "Here are credit card transactions; flag the weird ones." This gives us anomaly detection.
Think of it like handing someone a mixed jar of LEGO pieces and saying, "Sort these somehow." They might group by colour, shape, or size. There is no single right answer. They just have to find a structure that makes sense.
Reinforcement learning: Here, the model is an agent that takes actions, receives rewards or penalties, and gradually learns which actions pay off. It is learning by trial and error. Think of a bot teaching itself chess by playing against itself, or a robot learning to walk by falling a lot. Powerful, but used less often in everyday business problems. We will mention it occasionally, but we will not dive deep into it in this series.
4. A Quick Mental Map:
When someone shows us a problem and asks which flavor of ML it belongs to, one simple question helps a lot.
"Do we have labels for what we want to predict?"
Flavor Data has answers? Example task
Supervised
Yes
Predict a house price
Unsupervised
No
Group similar customers
Reinforcement
No (uses rewards)
Train a game-playing bot
That one question separates the supervised from the rest. From there, the next sub-question is whether we are predicting a number (regression) or a category (classification).
Before we close out the mental map, a small thought to sit with is, if we wanted to build a Netflix-style recommender, the kind that says "users who liked X also liked Y", which flavor would we say that is? Mostly unsupervised, since the model is finding hidden patterns in who likes what. But real systems also borrow supervised signals from explicit ratings.
In other words, these categories are thinking tools, not strict rules. Real ML systems often mix approaches, and that is perfectly normal.
5. A Few Common Confusions Cleared:
Before we close, here are a few questions beginners often have about ML.
- Is ML the same as AI?
- No. AI is the big umbrella – anything that mimics intelligence.
- ML is one branch of AI, the branch that learns from data instead of being explicitly programmed.
- Is ML the same as deep learning?
- Again, no. Deep learning is a sub-branch of ML that uses neural networks.
- We are skipping it in this series and focusing on classical ML.
- Do I always need huge amounts of data?
- For deep learning, yes. For classical ML, often a few thousand examples are enough.
- What is the difference between a "model" and an "algorithm"?
- An algorithm is the recipe (for example, "fit a line").
- A model is what you get after running that recipe on actual data (for example, the specific line y = 2x + 3).
- Which flavor matters most for interviews? Supervised, by a wide margin. Know it cold. Know unsupervised, at a solid intuition level. And just be aware that reinforcement learning exists.
6. If This Came In An Interview:
A few warm-up questions to be ready for, with one-line answers.
- What is machine learning?
- A way of programming where the computer learns rules from examples, instead of being given the rules by us.
- Inputs (X) go in, predictions (ŷ) come out, we compare to the truth (y) and adjust.
- What is the difference between AI, ML, and deep learning?
- AI is the umbrella (anything that mimics intelligence).
- ML is the branch of AI that learns from data.
- Deep Learning is the sub-branch of ML that uses neural networks.
- Supervised vs Unsupervised vs Reinforcement Learning?
- Supervised — data has labels; learn a mapping from X to Y.
- Unsupervised — no labels; find structure on our own.
- Reinforcement — no labels; learn from rewards through trial and error.
- Regression vs Classification: Both are supervised. Regression predicts a number (house price). Classification predicts a category (spam or not-spam).
- Model vs Algorithm: An algorithm is the recipe ("fit a line"). A model is what we get after running that recipe on actual data (the specific line
y = 2x + 3). - Which flavor matters most in industry? Supervised, by a wide margin. Around 80% of real-world ML is supervised, which is why most of this series lives there.
- What is generalisation, and why does it matter? Doing well on data the model has never seen, not just the data it trained on. It is the real point of ML and the question we will tackle properly on Day 2.
7. Summing It Up:
If we remember one thing from today, it is that we don't write rules. We show examples.
The machine figures out the rest.
The flavor of ML we pick depends on one question.
Do we have answers attached to our data? Supervised if yes, unsupervised if no, reinforcement if the answers arrive as rewards. And the deeper goal we will keep coming back to is generalisation. Doing well on data the model has never seen, not just the data it trained on. That is the real point of ML, and it is where Day 2 starts.
Coming Up on Day 2
How do we actually know if a model learned, or if it just memorised the training data? That is the question we tackle tomorrow, when we meet one of the most important and most painful concepts in ML — the train-test split and overfitting. We will also see why a model that scores one hundred percent on its training data is almost always a disaster waiting to happen.
That's all for today. Let's meet up again tomorrow with Day 2.
Thanks for reading.
Cheers!