Day 15: Random Forest — Wisdom of the Crowd
Day 15: Random Forest — Wisdom of the Crowd
 Parathan Thiyagalingam
Parathan Thiyagalingam
A single decision tree is fragile. Today we fix that with one of the most famous ideas in ML: instead of trusting one tree, trust a thousand. Random Forest is the most common "first real model" in industry, and almost always a strong baseline on tabular data.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Ensemble: Combining many models into one (by averaging or voting).
- Bagging: Bootstrap Aggregating. Train each tree on a random sample of the data with replacement.
- Bootstrap sample: A random subset drawn with replacement. Some rows appear multiple times, some not at all.
- Feature randomness: At each split, the tree only considers a random subset of features.
- OOB (Out-Of-Bag) score: A free validation score using rows each tree did not see during training.
- n_estimators: How many trees to grow.
1. The Wisdom of Crowds:
There is a famous experiment. Ask one thousand people to guess the weight of an ox. Most are wrong. But the average of all guesses is shockingly close to the true weight.
Why?
Because each person's error is random. When we average many random errors, they cancel out. The signal survives.
Random Forest applies this same idea to decision trees. Each tree is mediocre on its own, but a forest of mediocre trees, voting together, is excellent.

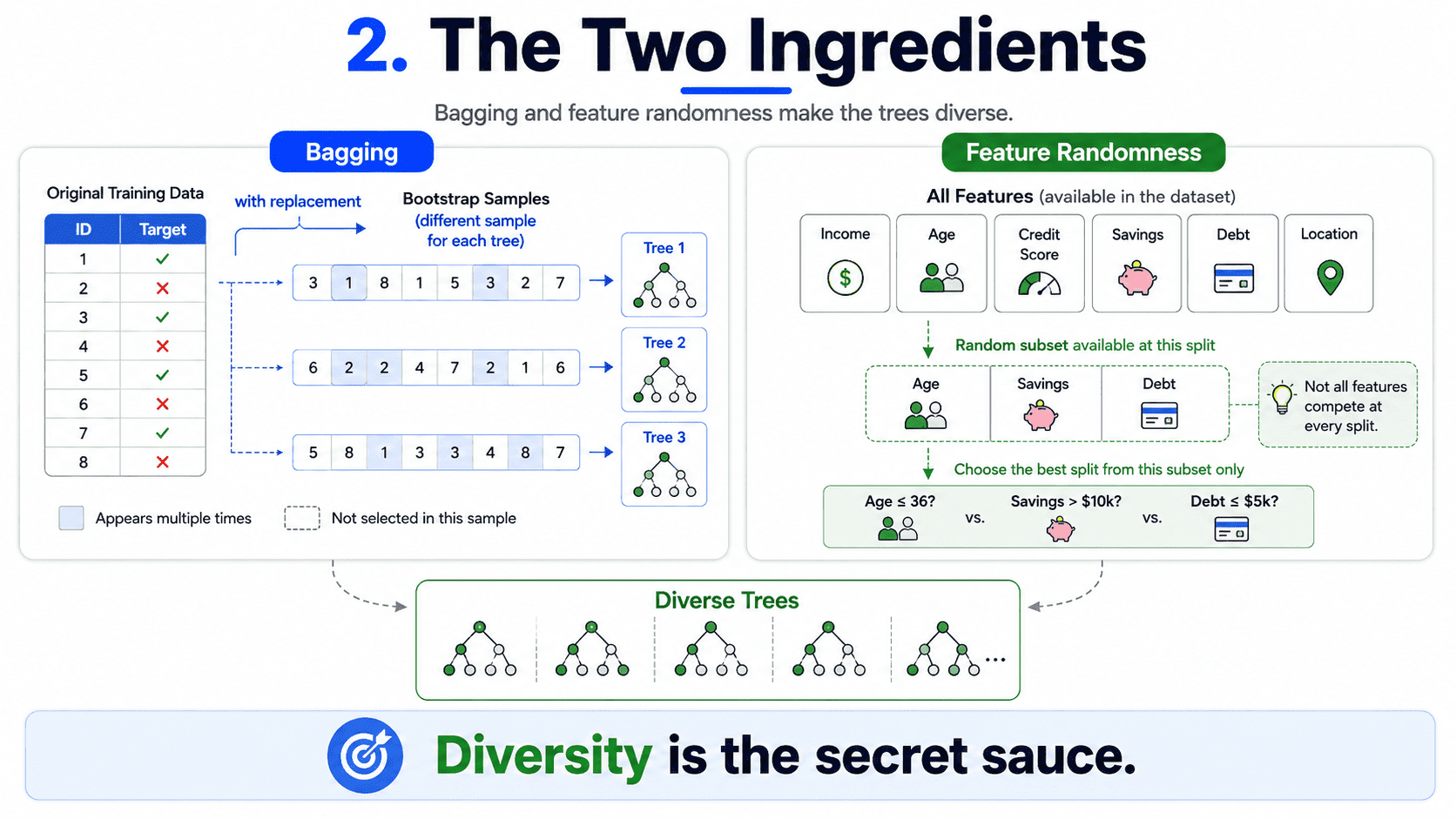
2. The Two Ingredients:
Two clever tricks turn one tree into a forest.
Bagging (Bootstrap Aggregating). Each tree is trained on a different random sample of the training data, drawn with replacement. Some rows show up multiple times in a tree's training set, and some do not show up at all. Each tree sees a slightly different "world" and learns slightly different rules.
Feature randomness. When picking a split, each tree only considers a random subset of features, not all of them. The default for classification is to try the square root of the total feature count per split. This forces trees to disagree with each other. Without it, every tree would pick the same dominant feature first, and the trees would be too similar to help each other.
Bagging plus feature randomness equals trees that are diverse. Diversity is the secret sauce.
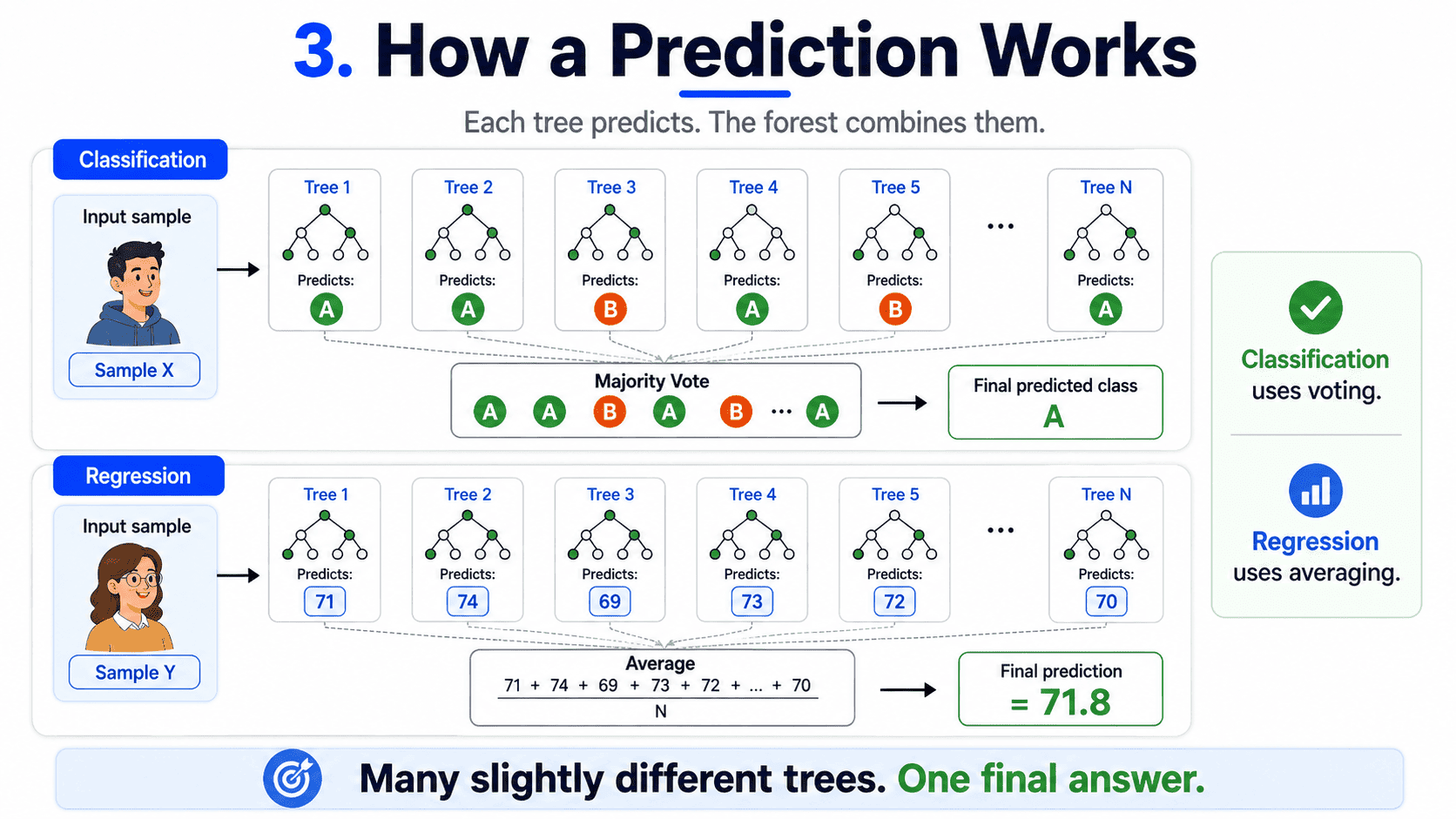
3. How a Prediction Works:
For classification:
- Run the input through all 500 (or however many) trees.
- Each tree votes for a class.
- The class with the most votes wins.
For regression, average the trees' predictions instead of voting. Many slightly-different trees voting together. That is the entire algorithm.
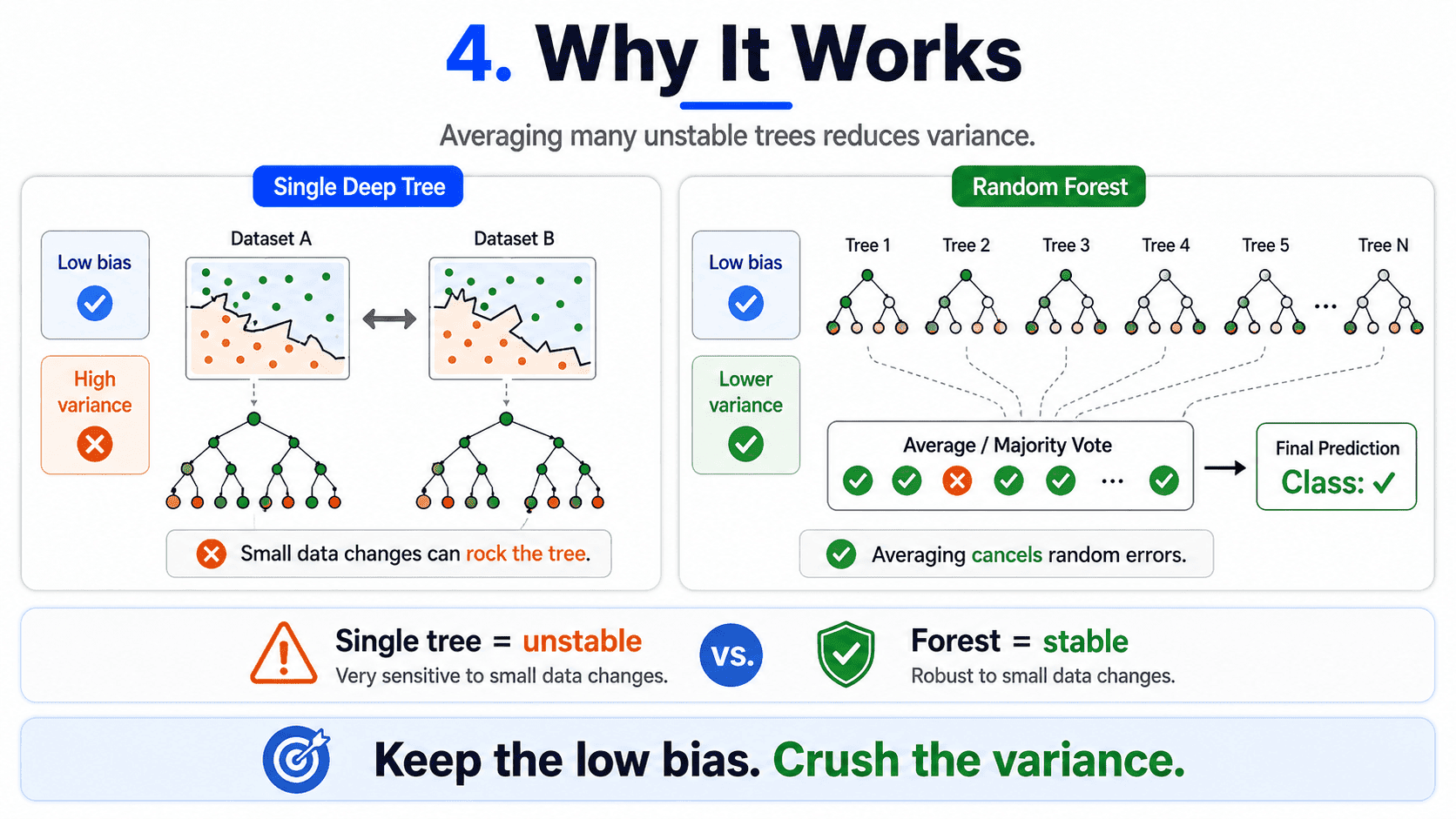
4. Why It Works (Through the Bias-Variance Lens):
Recall Day 3: Bias-Variance Tradeoff — Why Models Fail.
- A single deep tree has low bias and high variance. It memorises, and a small data change rocks it.
- Averaging many high-variance, low-bias models keeps the low bias and crushes the variance.
The forest stays as accurate on average as a single tree but is far more stable. Overfitting drops dramatically. This is the core trick behind every "bagging" method: combine high-variance learners to get a lower-variance one.
5. Random Forest's Most Loved Properties:
- Works out of the box. Default settings are usually decent.
- No scaling needed. Inherits this from trees.
- Handles missing values, categorical features, and mixed types. Robust.
- Built-in feature importance. Aggregated across all trees.
- Hard to overfit. Adding more trees does not hurt, it just gets slower.
- Parallelisable. Trees train independently.

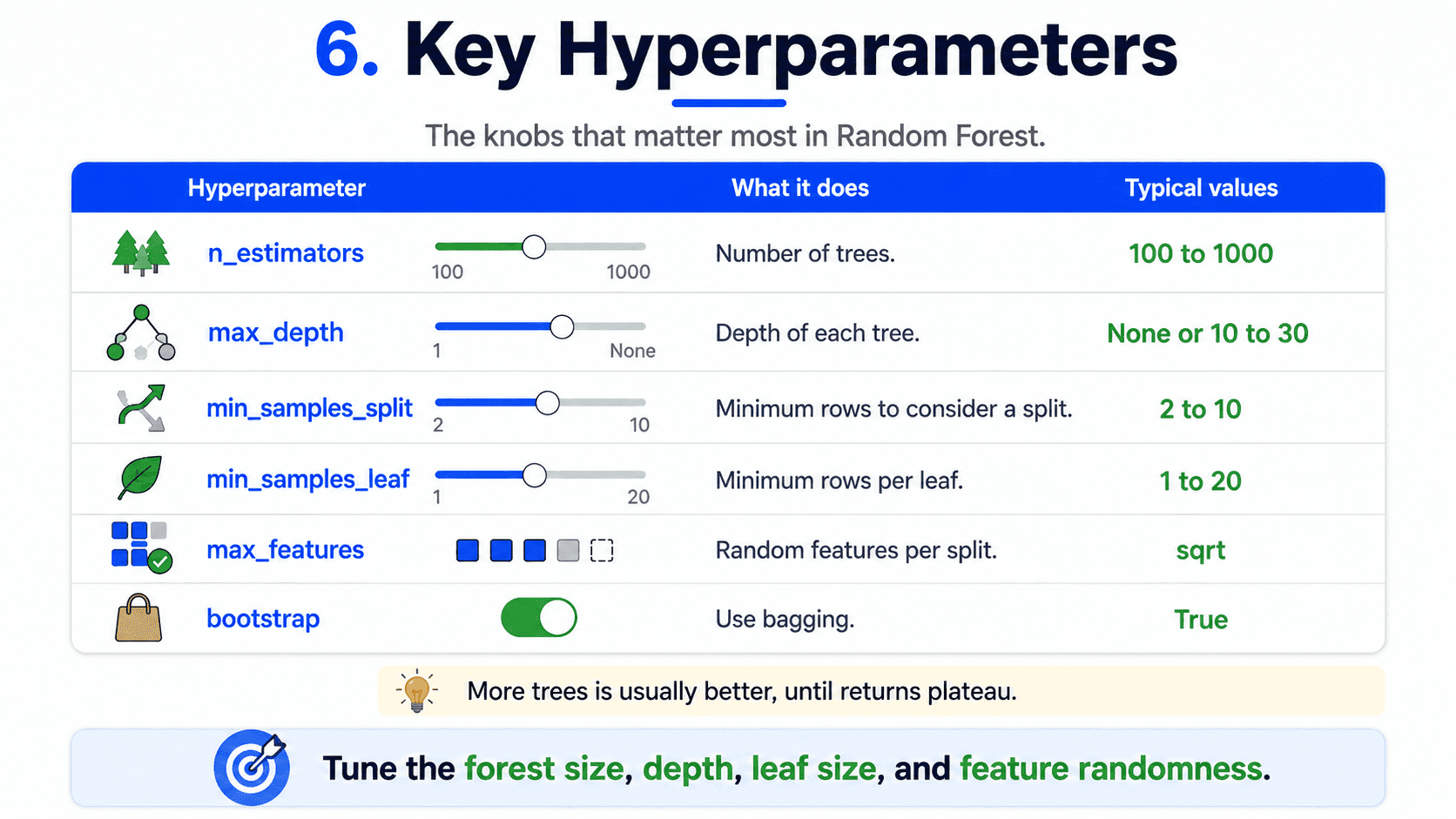
6. Key Hyperparameters:
The ones that matter most.
| Hyperparameter | What it does | Typical values |
|---|---|---|
n_estimators |
Number of trees | 100 → 1000 |
max_depth |
Depth of each tree | None or 10–30 |
min_samples_split |
Min rows to consider a split | 2–10 |
min_samples_leaf |
Min rows per leaf | 1–20 |
max_features |
Random features per split | 'sqrt' (default) |
bootstrap |
Use bagging? | True (default) |
A hidden truth. More trees is almost always better (slower, but better). We stop adding trees when the cross-validation score stops improving.
7. The Code:
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(
n_estimators=500,
max_depth=20,
min_samples_leaf=5,
n_jobs=-1, # use all CPU cores
random_state=42
)
rf.fit(X_train, y_train)
print(rf.score(X_test, y_test))
import pandas as pd
print(pd.Series(rf.feature_importances_, index=feature_names).sort_values(ascending=False))
n_jobs=-1 parallelises across all CPU cores. Random Forest scales beautifully.

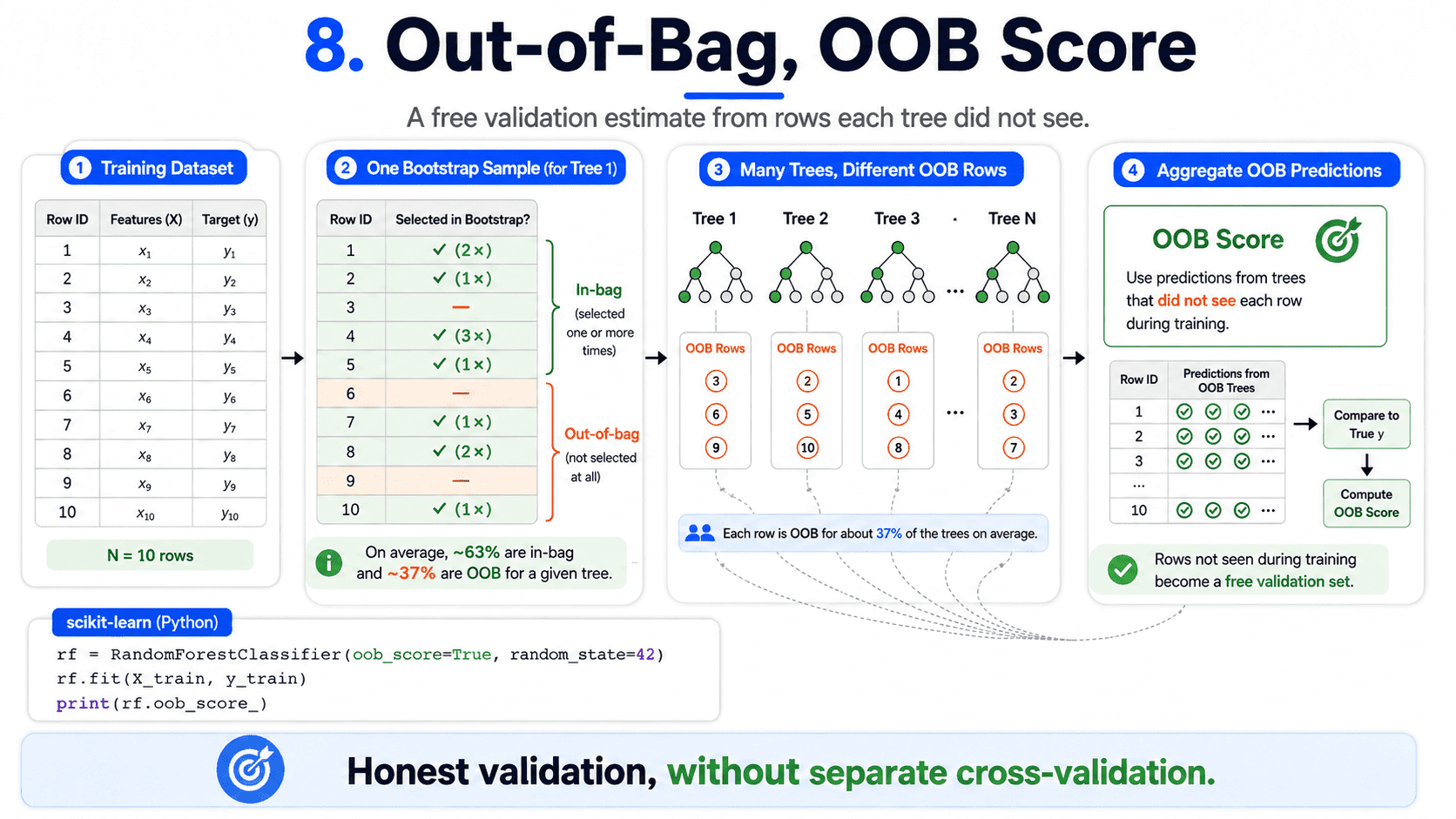
8. Out-of-Bag (OOB) Score:
When each tree is bagged, about 37% of training rows are randomly left out for that tree. The forest can use these "out-of-bag" rows as a free validation set.
rf = RandomForestClassifier(oob_score=True, random_state=42)
rf.fit(X_train, y_train)
print(rf.oob_score_)
We get a built-in honest estimate of generalisation without doing our own CV. Lovely.
9. When Random Forest Wins, When It Loses:
It wins on tabular data (the bread and butter of business ML), when we want a strong baseline without much tuning, when we need feature importances, when we need robustness against outliers and weird features, and on mixed feature types.
It loses on image, audio, or sequence data (deep learning wins there). When we need the absolute best score (gradient boosting tomorrow often beats RF by a few points).
On very high-dimensional sparse data (text bag-of-words), Naive Bayes or linear models often outperform. And when inference must be ultra-fast, since 500 trees is slower than Logistic Regression.
The underrated practical truth. Random Forest is almost never the best model, but it is almost always the easiest good model. We can throw it at any tabular problem with minimal preprocessing, and it will give us a reasonable baseline in minutes.
A rule of thumb in industry. Start with Random Forest to establish a baseline. Then try XGBoost or LightGBM to beat it. If XGBoost cannot beat RF by a meaningful margin, just ship RF.
A small thought to sit with. Suppose we trained a Random Forest with n_estimators=500 and got 92% accuracy. We bump it to 5000 trees and the accuracy creeps up to 92.1%, but training takes 10× longer.

What is the diagnosis?
We hit diminishing returns. Random Forest accuracy plateaus once we have enough trees. Past that point, we are paying compute for nothing. Drop back to 500 and save the time for tuning depth, leaf size, or trying gradient boosting.
10. A Few Common Confusions Cleared:
- What is "bagging" again? Bootstrap Aggregating. Bootstrap means random sampling with replacement. Aggregating means averaging or voting.
- Can Random Forest overfit? In theory yes, but in practice it is very hard. Adding more trees rarely makes it worse. Setting
max_depthtoo high on tiny data is the main risk. - Does scaling help Random Forest? No. Trees use thresholds, scale is irrelevant.
- RF vs XGBoost, which to use? RF when we want easy and robust. XGBoost when we want maximum performance and are willing to tune. Tomorrow we will see why.
- Common interview question: "What is the difference between Bagging and Boosting?" Bagging trains models in parallel on different random data subsets and averages them (Random Forest). Boosting trains models sequentially, each correcting the previous ones' mistakes (XGBoost). Different philosophies, same goal: combine weak learners into a strong one.
11. If This Came In An Interview:
A few questions to be ready for, with one-line answers.
- What is Random Forest? An ensemble of decision trees. Each tree is trained on a random subset of data (with replacement) and a random subset of features. Predictions are aggregated by voting (classification) or averaging (regression).
- What is bagging? Bootstrap Aggregating. Training many models on random bootstrap samples and combining their outputs. Reduces variance.
- Why does feature randomness help? It forces trees to disagree. Without it, every tree would pick the same dominant feature first, and the trees would be too similar to help each other.
- Bagging vs Boosting? Bagging trains models in parallel on different random data and averages them (variance reduction). Boosting trains models sequentially, each correcting the previous's mistakes (bias reduction).
- Can Random Forest overfit? In theory yes, but it is much harder than for a single tree. Adding more trees rarely hurts.
- What is OOB score? Out-Of-Bag score. Uses the ~37% of rows each tree did not see during training as a free validation set.
12. Summing It Up:
If we remember one thing from today, it is this: a forest of mediocre trees, voting, beats one great tree. The randomness creates diversity, and the averaging kills variance. It is the most "just works" model in classical ML. Strong baseline. Minimal tuning. No scaling. Almost never the best, almost always a great default.
Coming Up on Day 16: Gradient Boosting & XGBoost — Learning from Mistakes
Random Forest averages many independent trees. Tomorrow we meet a smarter idea. Train trees one after another, with each tree correcting the previous tree's mistakes. The result is the algorithm that has dominated tabular ML competitions for a decade: Gradient Boosting and XGBoost.
That's all for today. Let's meet up again tomorrow with Day 16.
Thanks for reading.
Cheers!