Day 14: Decision Trees — Twenty Questions Automated
Day 14: Decision Trees — Twenty Questions Automated
 Parathan Thiyagalingam
Parathan Thiyagalingam
If we have ever played the game Twenty Questions, we have already done decision trees in our head.
Today we automate that intuition. Decision Trees are the most interpretable model in classical ML, and they are also the foundation for the heavy-hitting ensembles we will meet over the next two days.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Node: A question in the tree (for example, "Income > $50k?").
- Leaf: A bottom of the tree, where the final prediction lives.
- Split: The chosen yes/no question at a node.
- Gini impurity / Entropy: Measures of how "mixed" a node is. The tree minimises these.
- max_depth, min_samples_leaf: The regularisation knobs that stop the tree from overfitting.
- Feature importance: A score for how much each feature reduced impurity across the splits where it appeared.
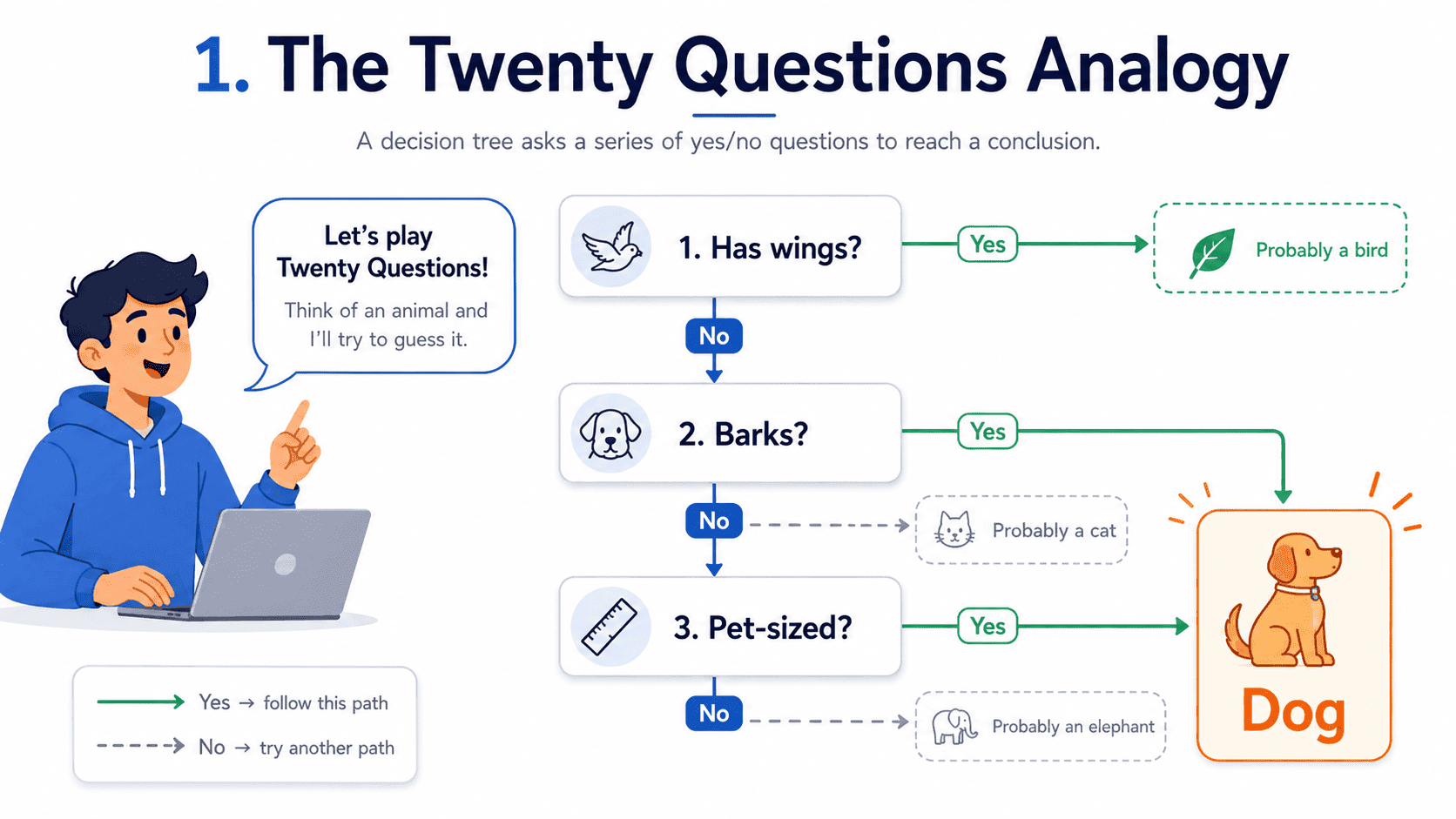
1. The Twenty Questions Analogy:
Someone is thinking of an animal. We ask:
- "Does it have wings?" → No.
- "Does it bark?" → Yes.
- "Is it small enough to be a pet?" → Yes.
We guess: dog.
Each question splits the possibilities. The right questions narrow things fast. The wrong questions waste time. A decision tree is exactly this: a sequence of yes/no questions leading to a final guess.
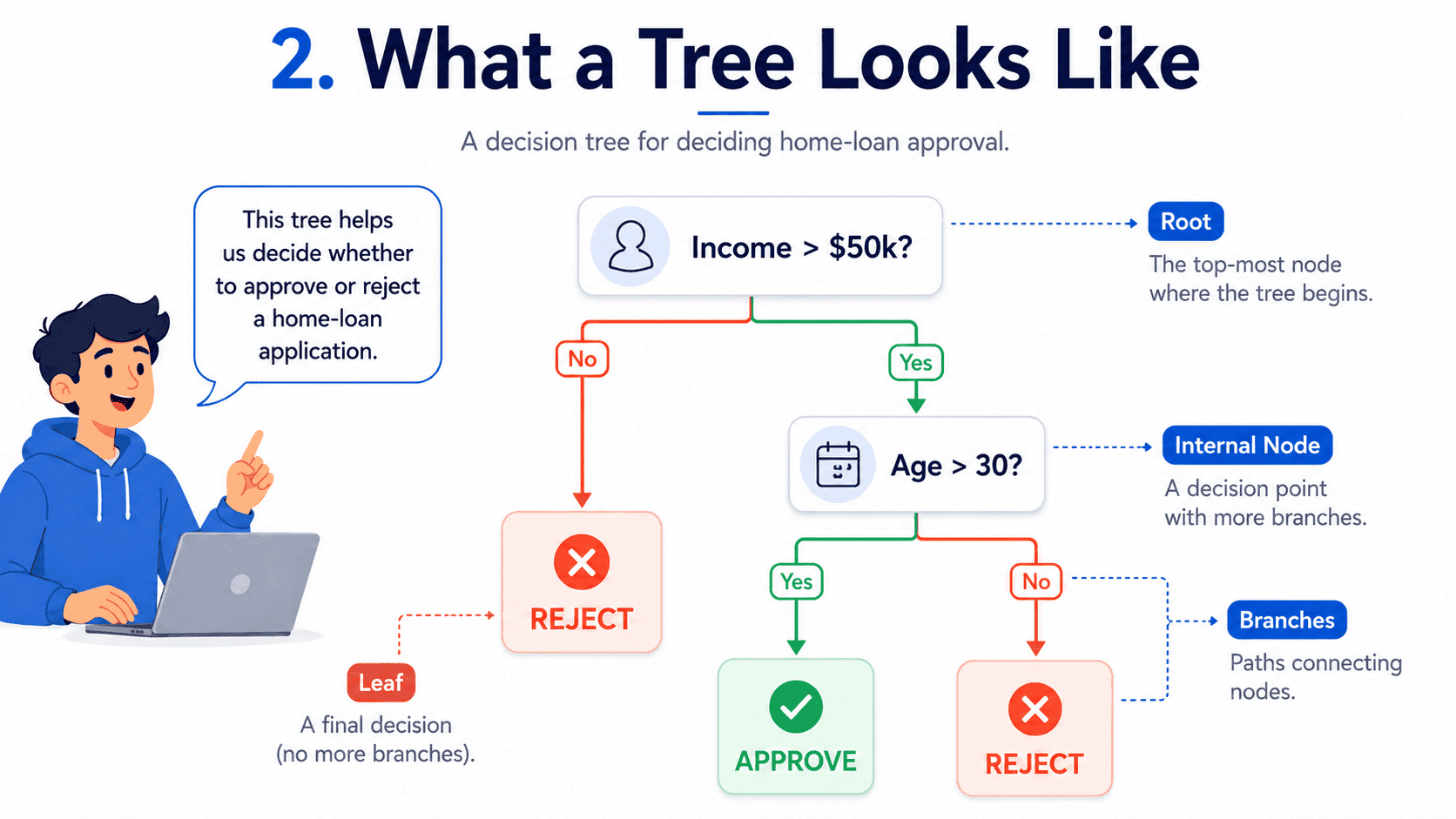
2. What a Tree Looks Like:
For predicting whether someone will buy a house:
Income > $50k?
/ \
Yes No
| |
Age > 30? REJECT
/ \
Yes No
| |
APPROVE REJECT
- Root: the first question (top of the tree).
- Internal nodes: middle questions.
- Leaves: final answers (bottom of each path).
- Branches: paths from question to answer.
We read the tree top to bottom. The route to the leaf is the model's reasoning. Anyone can follow it.
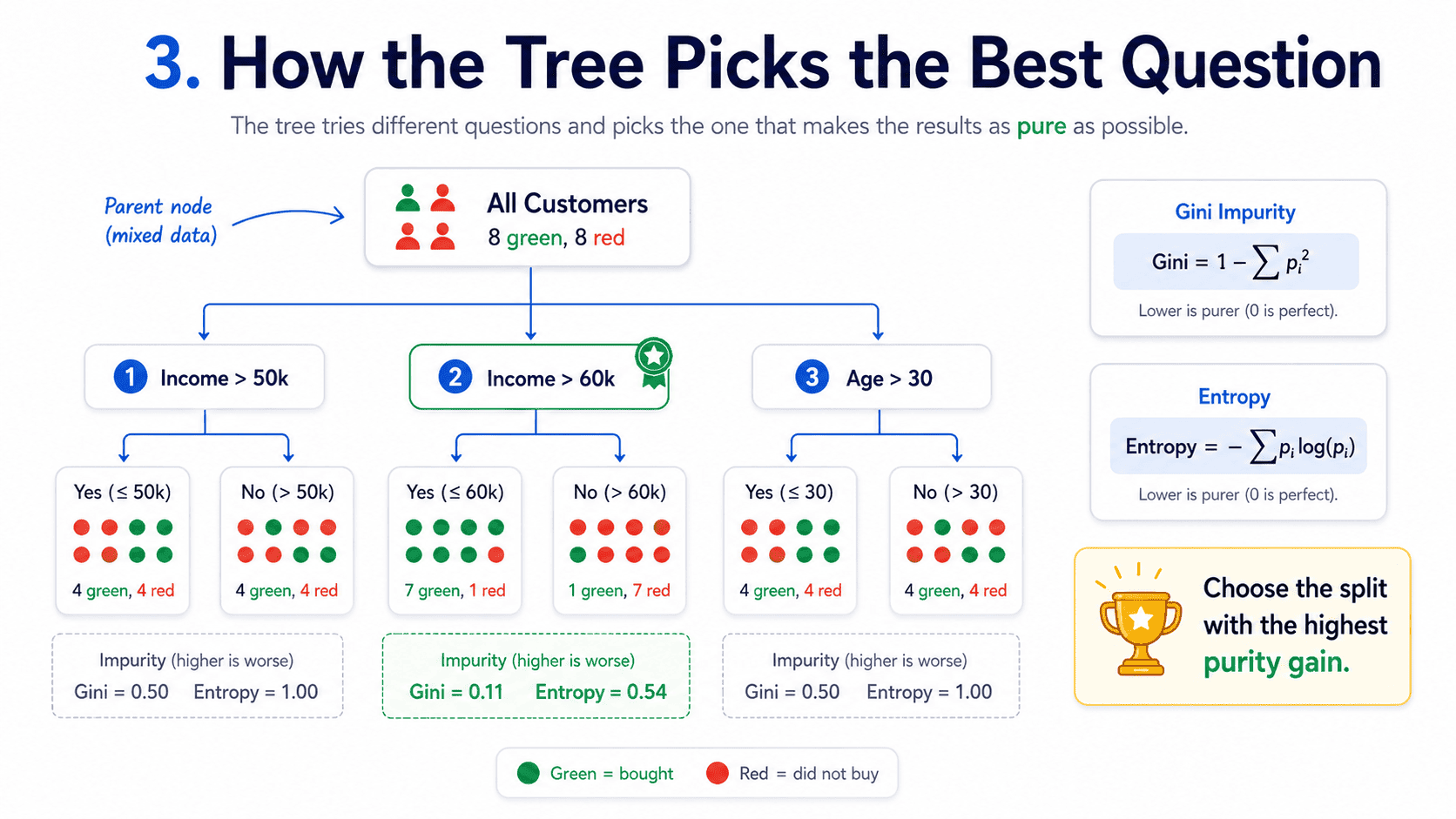
3. How Does the Tree Pick the Best Question?
At each node, the tree considers every possible split.
- "Income > 50k vs ≤ 50k"
- "Income > 60k vs ≤ 60k"
- "Age > 30 vs ≤ 30"
- ...
It scores each split by how "pure" the resulting groups are. A perfect split would put all "approve" cases on one side and all "reject" cases on the other.
Two common purity measures:
Gini Impurity.
Gini = 1 − Σ pᵢ²
It is the probability of misclassifying a randomly chosen point if we labelled it according to the group's distribution. Lower is better. A pure group has Gini = 0.
Entropy.
Entropy = − Σ pᵢ log(pᵢ)
This is the information-theory measure of disorder. Same direction. Lower is more pure.
Gini and entropy almost always agree. Gini is slightly faster and is sklearn's default. We do not need to fuss about which to choose.
The tree picks the split that maximises purity gain, then recurses. Greedy from top to bottom.
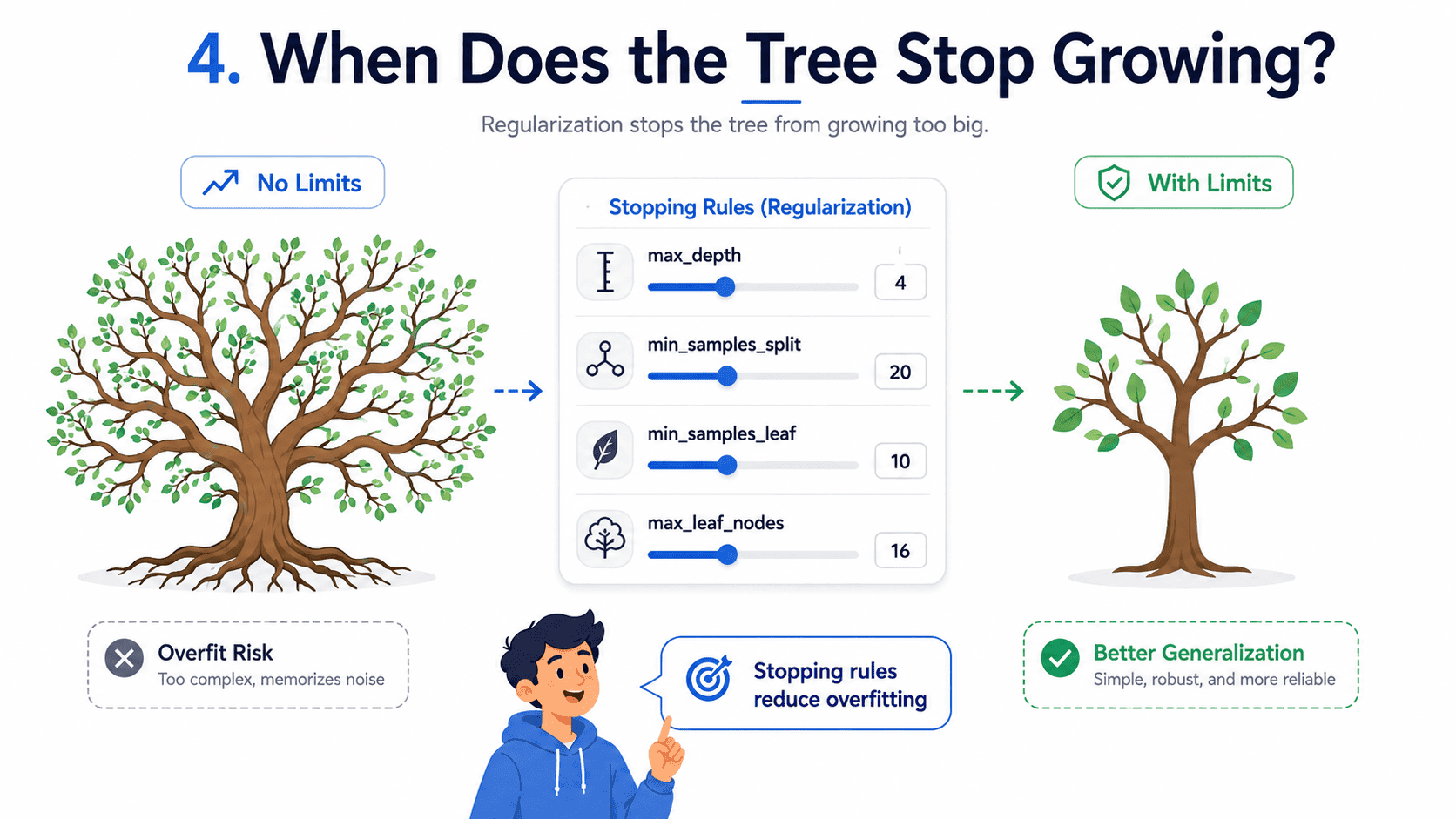
4. When Does the Tree Stop Growing?
A tree could keep splitting until every leaf has one row in it, which would memorise the training data perfectly and overfit hideously. So we cap it. Common stopping rules:
- max_depth: do not go deeper than N levels.
- min_samples_split: do not split a node with fewer than N rows.
- min_samples_leaf: every leaf must have at least N rows.
- max_leaf_nodes: cap the total number of leaves.
These are the tree's regularisation knobs. They push the Day 3: Bias-Variance Tradeoff — Why Models Fail toward higher bias and lower variance.
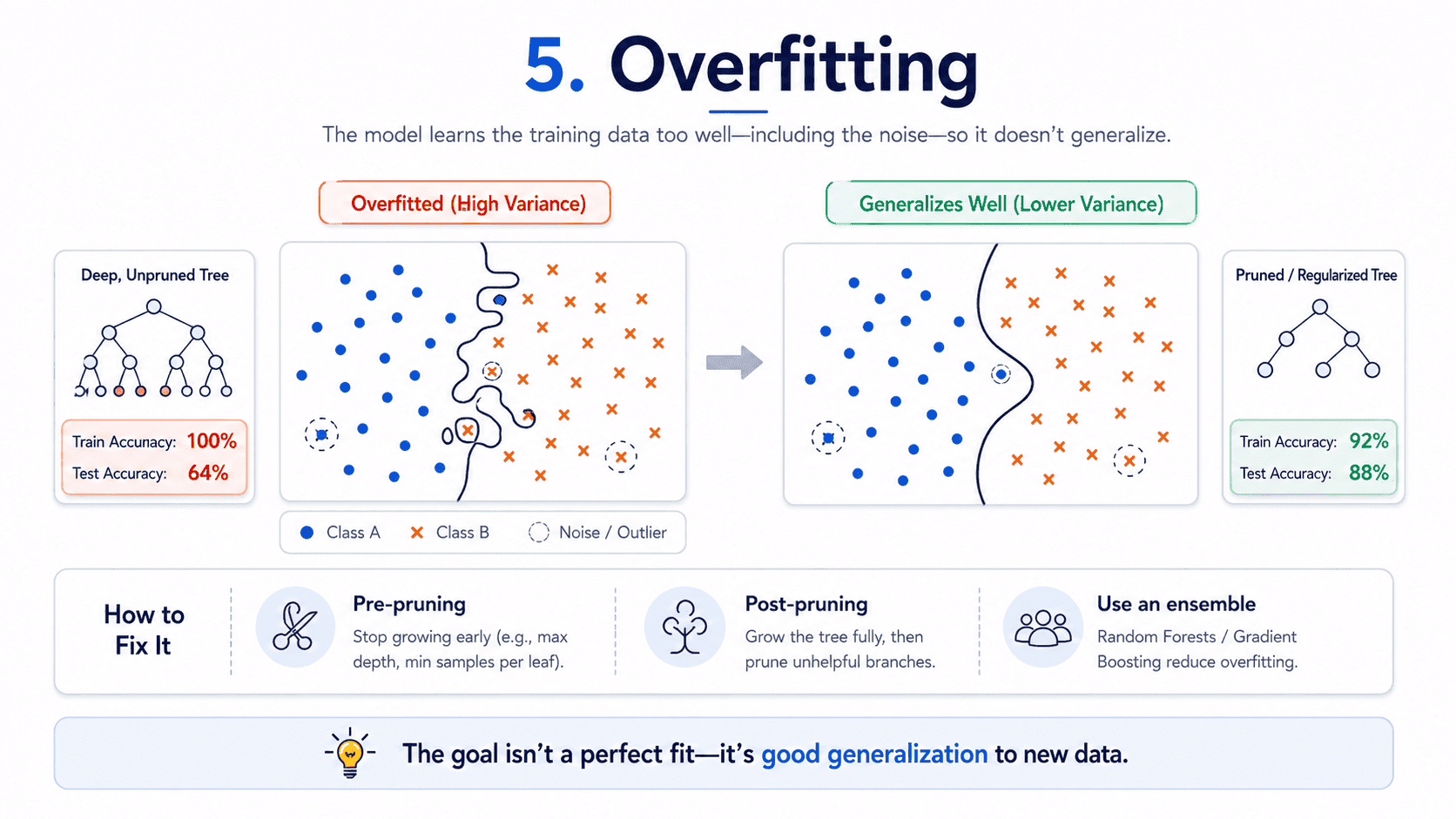
5. Overfitting:
Left unconstrained, a decision tree will overfit almost any dataset. A deep tree carves out tiny irregular regions to memorise noise.
The symptoms:
- Train accuracy = 100%.
- Test accuracy is mediocre.
- The decision boundary has visible "spikes" if we visualise it.
The fixes:
- Pre-pruning: set the stopping rules upfront (
max_depth=10, etc.). - Post-pruning: grow a big tree, then chop weak branches (sklearn does this via
ccp_alpha). - Use an ensemble: Random Forest Day 15: Random Forest — Wisdom of the Crowd is the gold-standard fix.
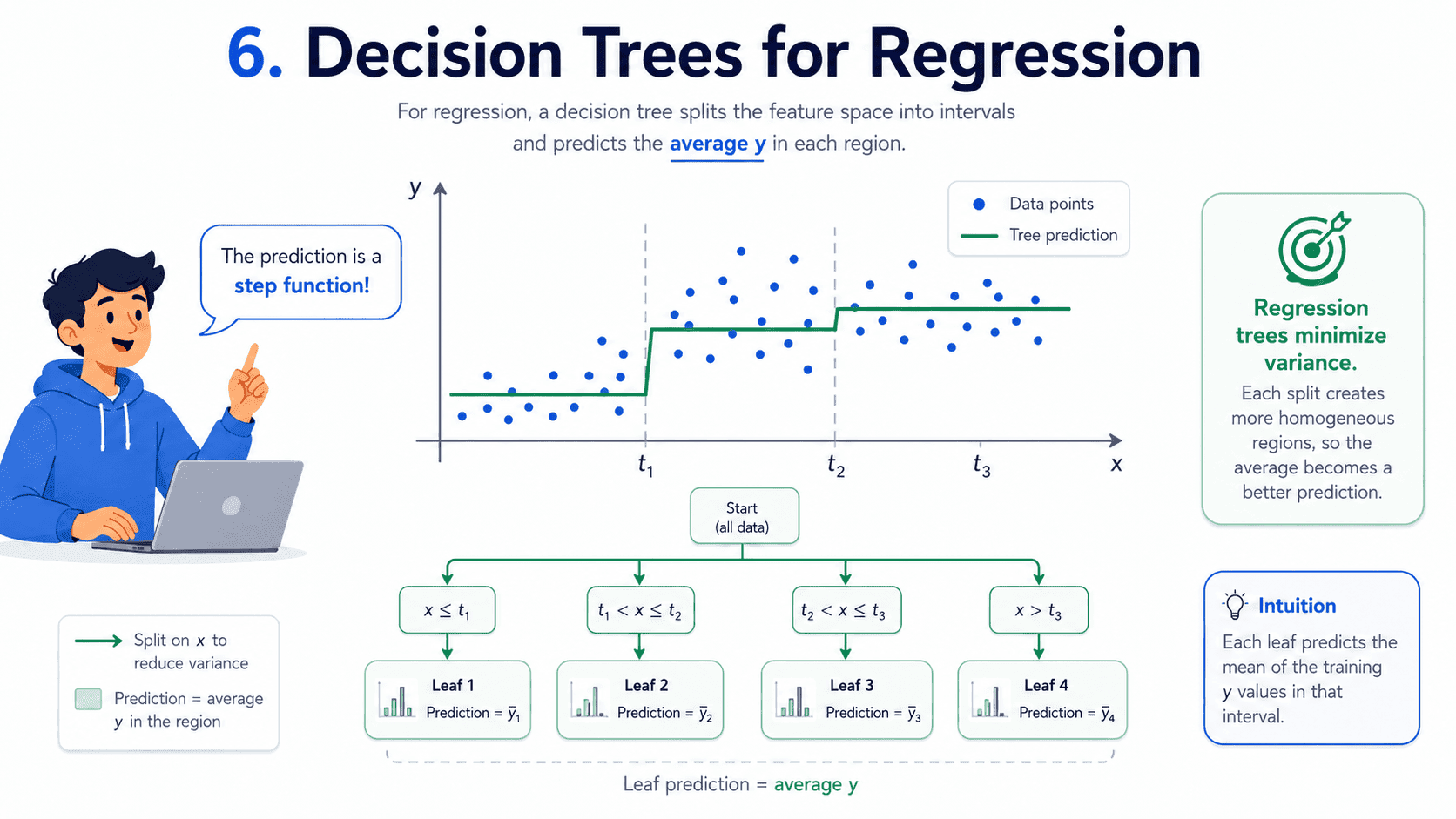
6. Decision Trees for Regression:
Same algorithm, slightly different splits. Instead of measuring class purity, regression trees use variance reduction: a good split makes the y-values in each group as similar as possible.
The prediction at a leaf is just the average of the training y values that landed in it. So a regression tree predicts a step function, a series of flat plateaus.
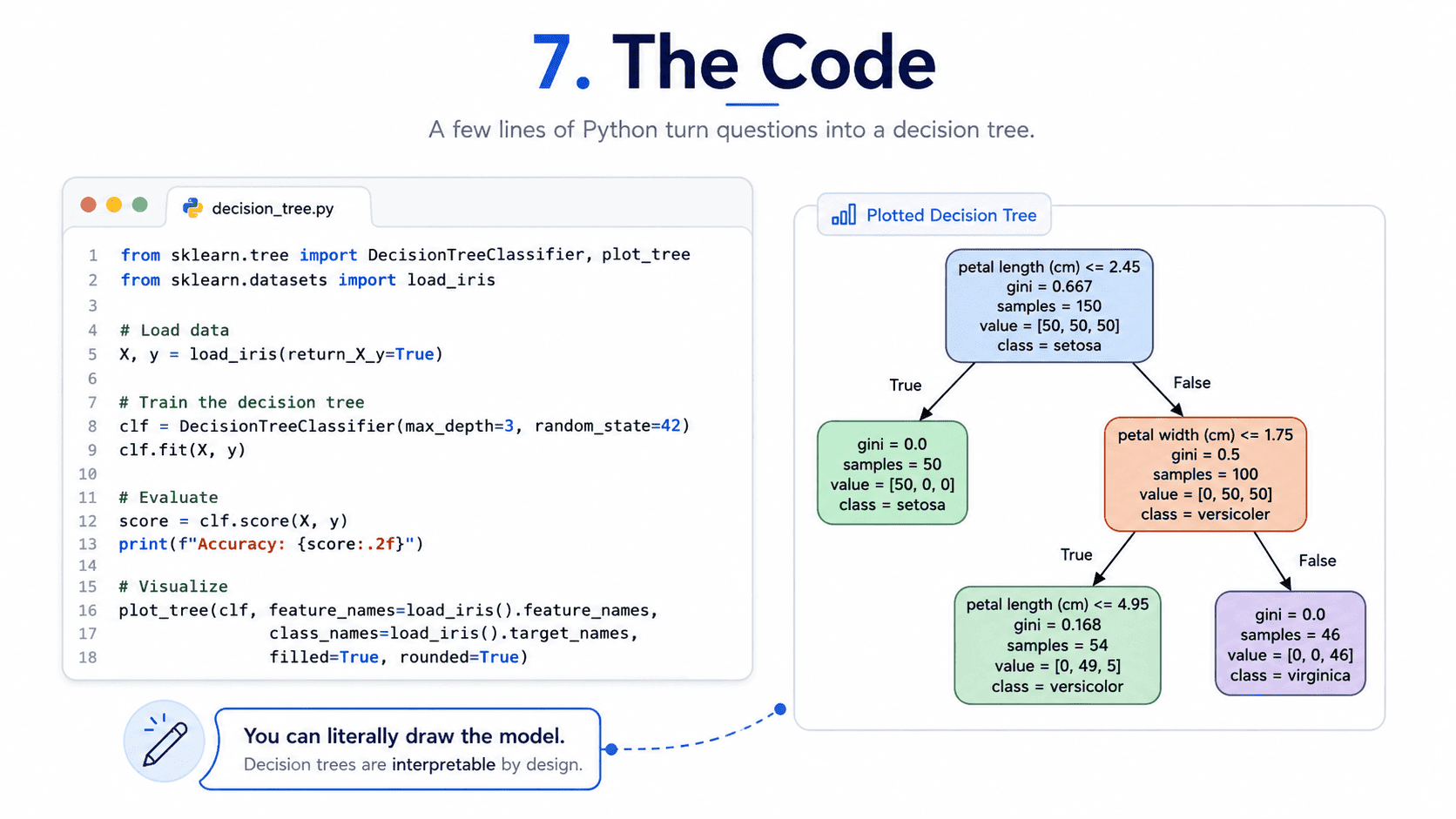
7. The Code:
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
tree = DecisionTreeClassifier(max_depth=5, min_samples_leaf=20, random_state=42)
tree.fit(X_train, y_train)
print(tree.score(X_test, y_test))
plt.figure(figsize=(20, 10))
plot_tree(tree, feature_names=feature_names, class_names=class_names, filled=True)
plt.show()
Yes, we can literally draw the model. Try doing that with Logistic Regression. We cannot.
8. Feature Importance for Free:
After training, we can ask the tree which features mattered most.
import pandas as pd
importance = pd.Series(tree.feature_importances_, index=feature_names)
print(importance.sort_values(ascending=False))
Each feature gets a score (0 to 1) based on how much it reduced impurity across the splits it appeared in. The most "asked about" features bubble to the top.
This is one of the most useful side-effects of using trees: we get interpretability and feature selection in one shot.

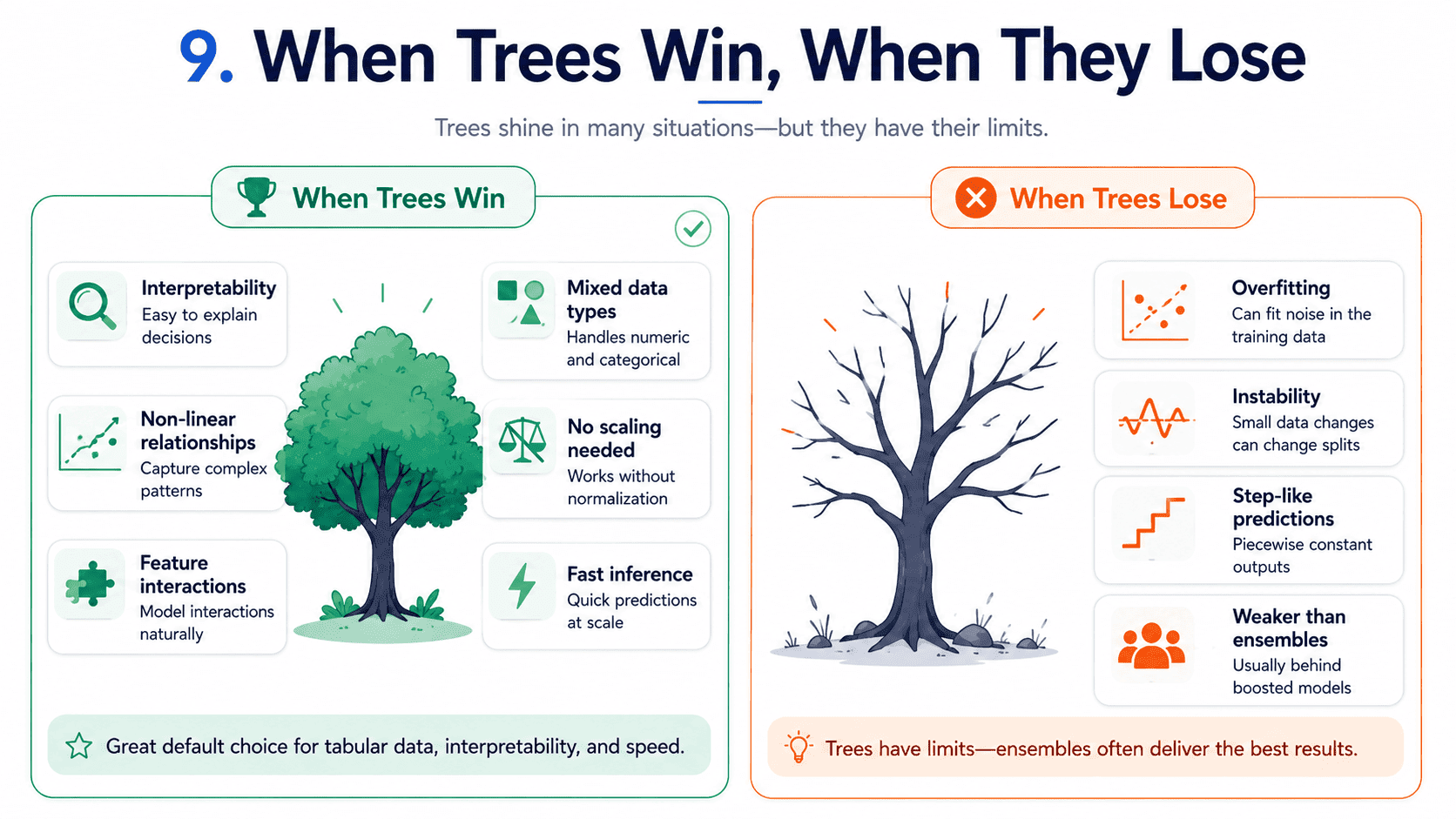
9. When Trees Win, When They Lose:
They win when we need an interpretable model (regulation, communication, debugging), when data has non-linear relationships and feature interactions, when we have mixed feature types (numeric plus categorical, no scaling needed), and when we need fast inference.
They lose when used alone, because they overfit easily. Small changes in data can radically change the tree (instability). They cannot model smooth relationships well; predictions look like steps. And for pure performance, ensembles (Random Forest, XGBoost) almost always beat a single tree.
A small thought to sit with. Suppose a friend trains a decision tree and brags about 100% train accuracy. We ask about test accuracy.
They say 64%. What is the diagnosis, and what would we change? Textbook overfitting. The tree was probably grown to full depth. We would cap max_depth (try 5 or 10), raise min_samples_leaf (try 10 to 50), or use Random Forest tomorrow.
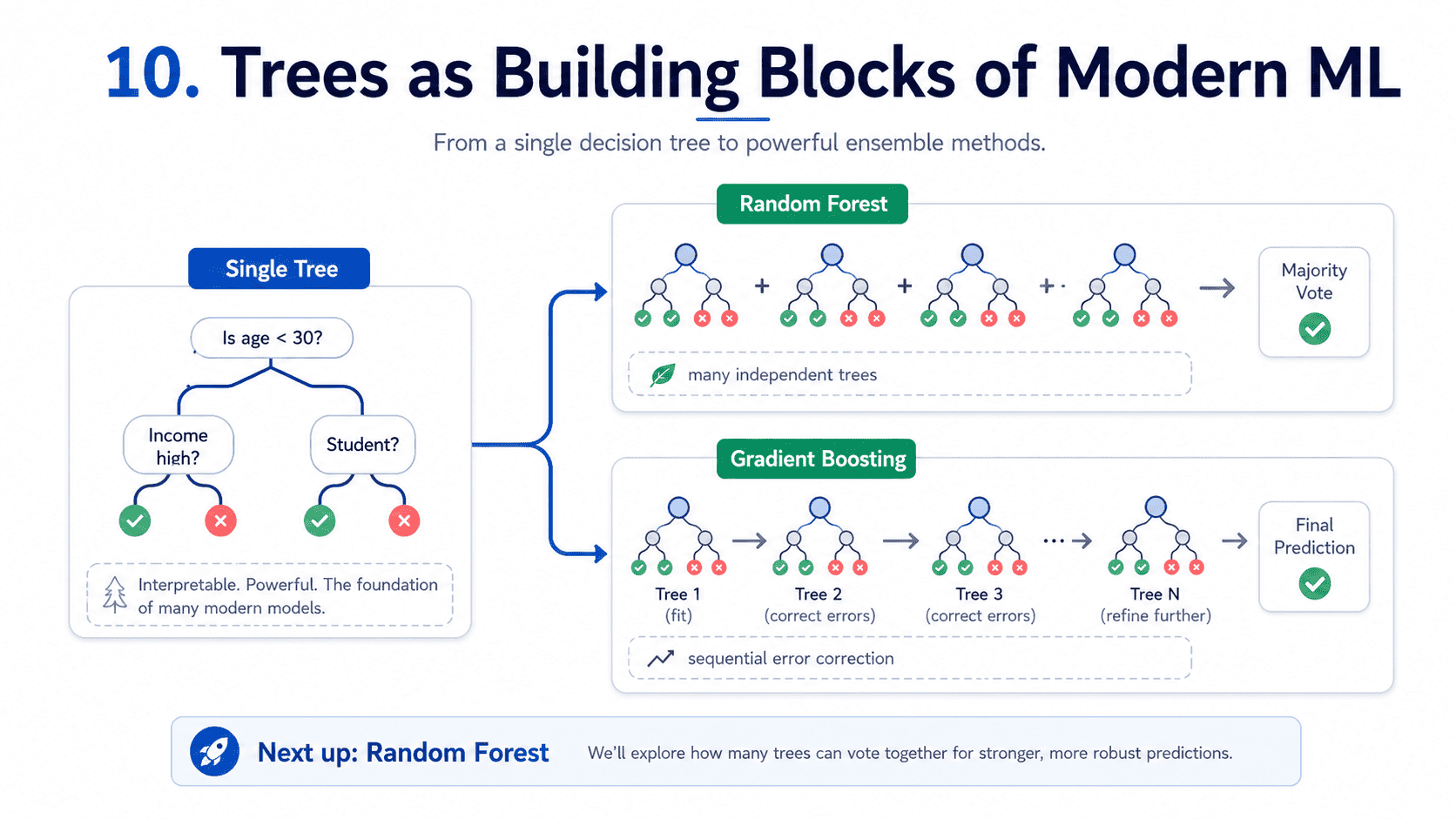
10. Trees as Building Blocks of Modern ML:
A single decision tree is fragile. But the next two days address this by combining many trees.
- Random Forest: many independent trees, voting.
- Gradient Boosting (XGBoost): many trees in sequence, each correcting the previous ones.
These two algorithms are the workhorses of structured-data ML. Almost every top Kaggle solution starts with one of them. The single tree we built today is the atom. Tomorrow we start assembling molecules.
11. A Few Common Confusions Cleared:
- Are trees a "white box" or "black box" model? White box. We can read the model directly. This is rare in ML and a huge selling point in regulated industries.
- Do trees need scaled features? No. Each split is a threshold on one feature, so the scale does not matter. Same with one-hot encoding. Trees handle raw numbers fine.
- What is the difference between Gini and Entropy? Almost nothing in practice. Gini is slightly faster to compute. Both measure node purity. Do not tune between them; tune
max_depthinstead. - Are decision trees prone to overfitting or underfitting by nature? Overfitting. A deep tree's variance is sky-high. That is why we regularise and (tomorrow) ensemble.
- Common interview question: "How does a decision tree decide where to split?" It evaluates every possible split on every feature, scores each by Gini or entropy reduction, and picks the best. Then it recurses. It stops when a stopping rule kicks in.
12. If This Came In An Interview:
A few questions to be ready for, with one-line answers.
- How does a decision tree decide where to split? It evaluates every possible split on every feature, scores each by purity gain (Gini or Entropy), and picks the best. Then it recurses.
- What is the difference between Gini and Entropy? Almost nothing in practice. Both measure node purity. Gini is slightly faster, sklearn uses it by default.
- Why do trees overfit? Because, left unconstrained, a deep tree carves out tiny regions to memorise individual training points.
- How do we control overfitting in a tree? Limit depth, set minimum samples per leaf, set minimum samples per split, or prune the grown tree.
- Do trees need feature scaling? No. Each split is a threshold on one feature, so the scale does not matter.
- What is feature importance in a tree? A score for each feature based on how much it reduced impurity across the splits where it appeared. Aggregated across trees in an ensemble.
13. Summing It Up:
If we remember one thing from today, it is this: a decision tree is just an automated game of Twenty Questions. It is interpretable, handles mixed data types, needs no scaling, and overfits aggressively if left alone. The remedies are depth limits, leaf-size limits, and (tomorrow) ensembling.
Coming Up on Day 15: Random Forest — Wisdom of the Crowd
A single tree memorises. But what if we train hundreds of them, each on a slightly different slice of the data, and let them vote? Magic happens, and we call that Random Forest, the most-used "first real model" in industry data science.
That's all for today. Let's meet up again tomorrow with Day 15.
Thanks for reading.
Cheers!