Day 11: Class Imbalance — Why Accuracy Lies
Day 11: Class Imbalance — Why Accuracy Lies
 Parathan Thiyagalingam
Parathan Thiyagalingam
A model that is 99% accurate at detecting fraud can be completely useless. It sounds like a riddle. It is not. It is one of the most common real-world ML problems, and a favourite interviewer trap.
Today we close the loop on metrics, thresholds, and the trap of accuracy.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Class imbalance: One class is much rarer than the other (fraud, disease, churn).
- SMOTE: Synthetic Minority Over-sampling. Generates new minority examples by interpolating between existing ones.
- Oversampling / Undersampling: Duplicate minority rows / drop majority rows to rebalance the training set.
- class_weight='balanced': A model parameter that tells the algorithm to penalise mistakes on the rare class more.
- Threshold tuning: Moving the cut-off above or below 0.5 to favour precision or recall.
- PR-AUC: Precision-Recall AUC. More honest than ROC-AUC under heavy imbalance.
1. The Setup:
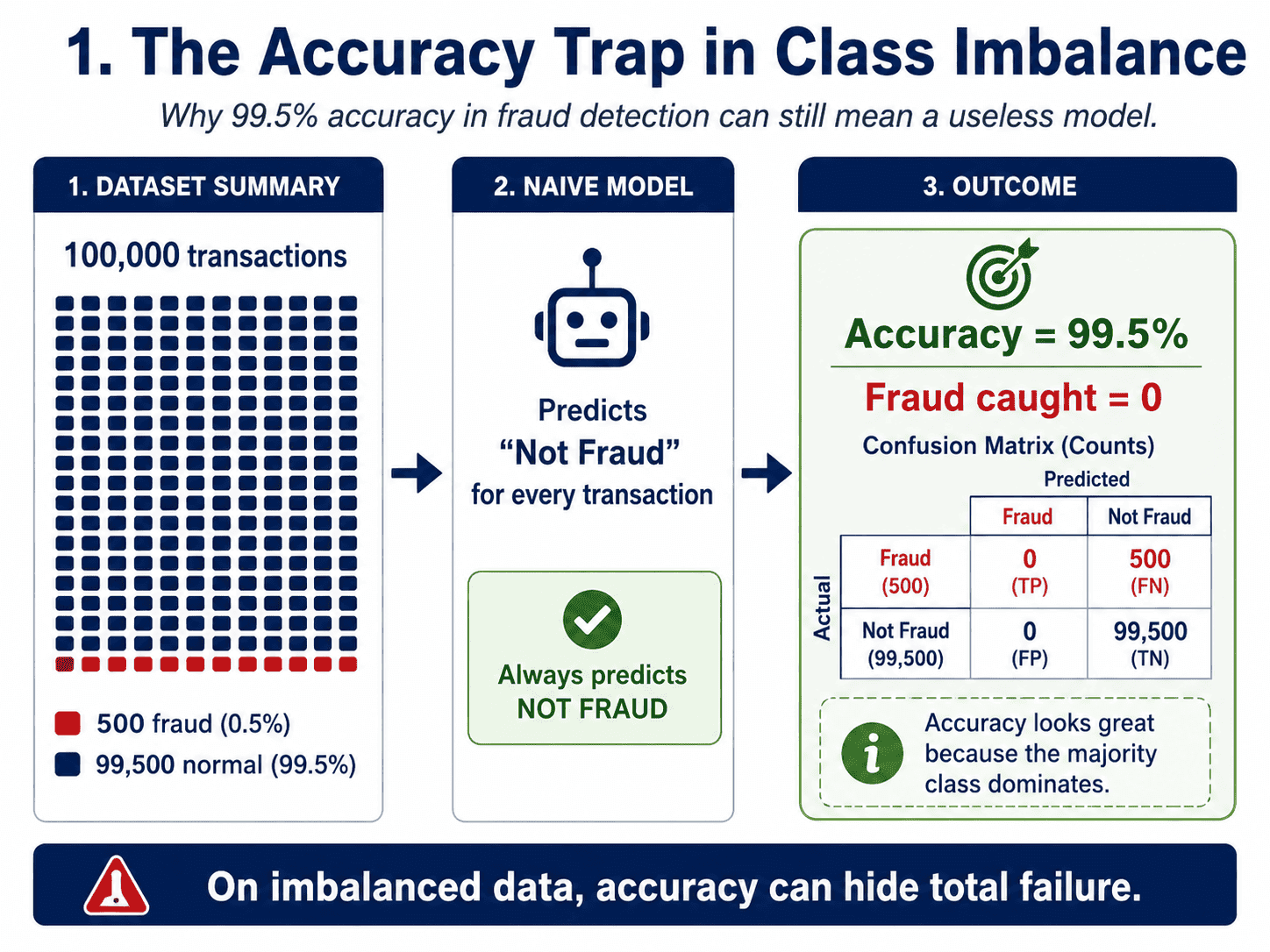
Suppose we are building a fraud detector. Our dataset has one hundred thousand transactions. Five hundred are fraud (0.5%). The rest are normal.
We train a model. It gets 99.5% accuracy. The manager celebrates. We frown.
Why?
Because a model that says "not fraud" to every single transaction also gets 99.5% accuracy. And it catches zero fraud. The model has learned nothing.
That is class imbalance. The majority class drowns out the signal, and accuracy makes the disaster look like a victory.
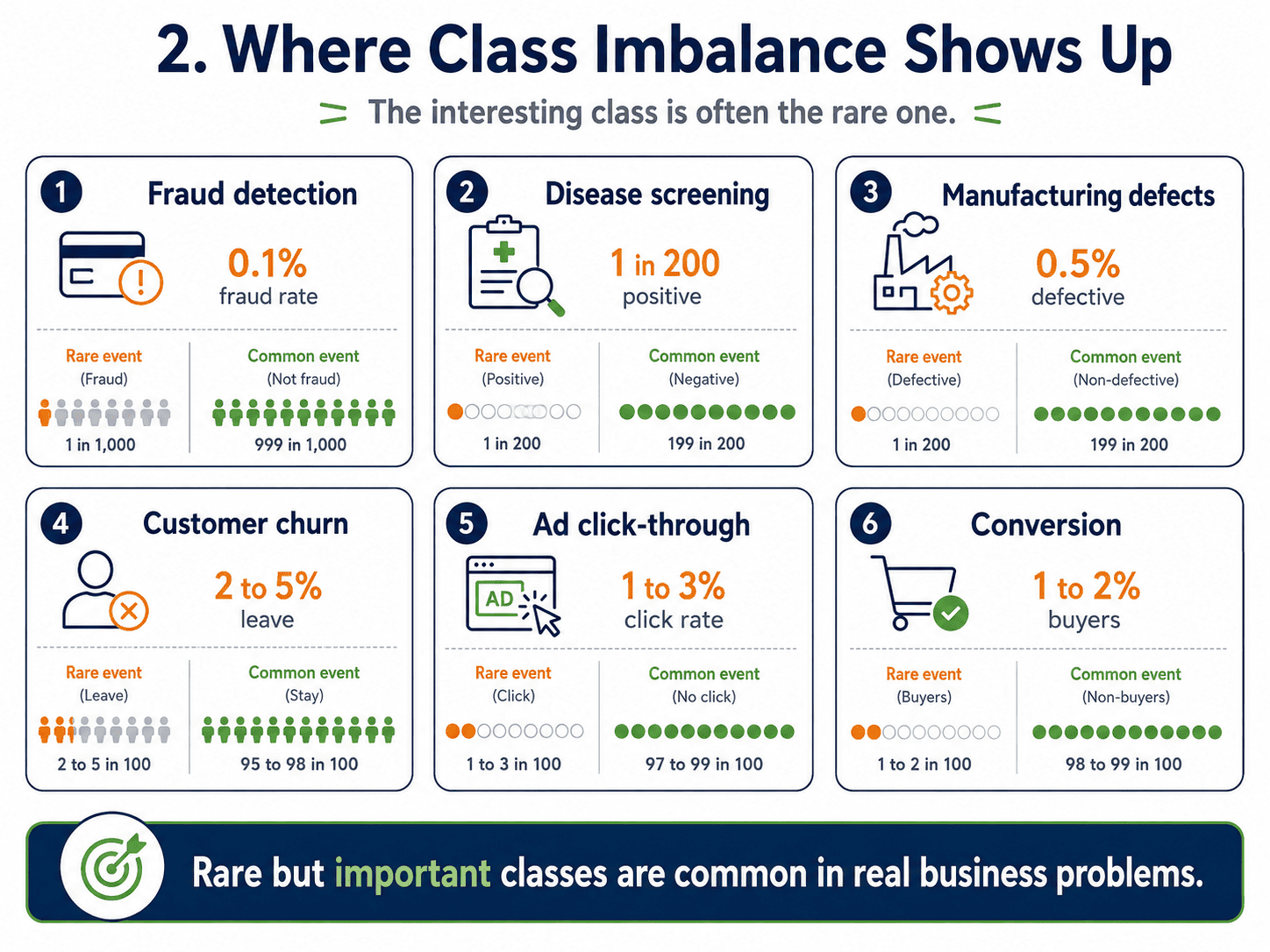
2. Where Imbalance Shows Up:
It is everywhere in business.
- Fraud detection: 0.1% fraud rate.
- Disease screening: 1 in 200 patients.
- Manufacturing defects: 0.5% defect rate.
- Churn: 2 to 5% of customers leave each month.
- Ad click-through: 1 to 3% click rate.
- Conversion: 1 to 2% of visitors actually buy.
Notice the pattern. The interesting class is almost always the rare one.
3. Stop Using Accuracy:
We covered this on Day 6: Evaluation Metrics — How Do We Know a Model is Good.
Now we apply it. For imbalanced data, we look at:
- Precision and Recall: the right tradeoff for the problem.
- F1 score: the harmonic compromise.
- Confusion matrix: the raw counts of TP, FP, FN, TN.
- Precision-Recall AUC: more honest than ROC-AUC on heavily imbalanced data.
For fraud specifically:
- Recall = TP / (TP + FN): what fraction of real fraud did we catch?
- Precision = TP / (TP + FP): when we flagged something as fraud, how often were we right?
These two are usually in tension. Both matter, in different ways for different problems.

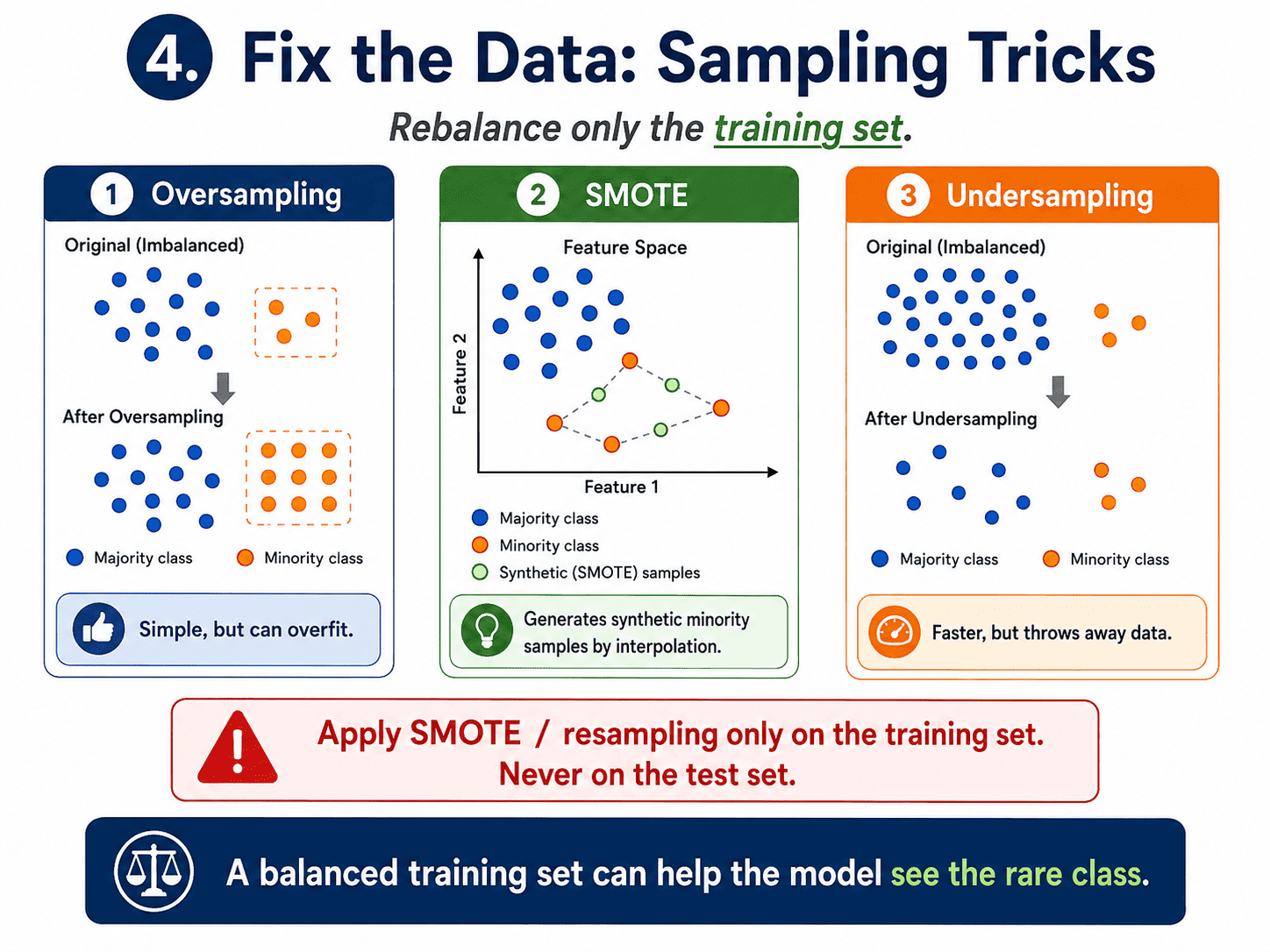
4. Fix the Data (Sampling Tricks):
Three flavors of rebalancing the training set.
Oversampling. Make copies of the rare class until the classes are balanced. Cheap, but risks overfitting because the model sees the same fraud examples many times.
SMOTE (Synthetic Minority Over-sampling Technique). Instead of copying, generate new minority examples by interpolating between existing ones. Less overfitting, more realistic data.
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X_train, y_train)
Important: apply SMOTE only on the training set, never on the test set. The test set must reflect the real-world distribution.
Undersampling. Throw away some normal examples until classes are balanced. Faster training, but we have thrown away data. Often the best is a combination: undersample the majority a bit and oversample the minority a bit, meeting in the middle.
5. Fix the Model (Class Weights):
A more elegant approach is to not change the data at all. Instead, we tell the model to care more about the minority class. Most sklearn models accept class_weight='balanced'.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)
Internally, mistakes on the minority class are weighted more heavily. The model learns to take them seriously.
A small piece of practical advice. Try class_weight='balanced' first. It is free, fast, and often as good as fancy resampling.

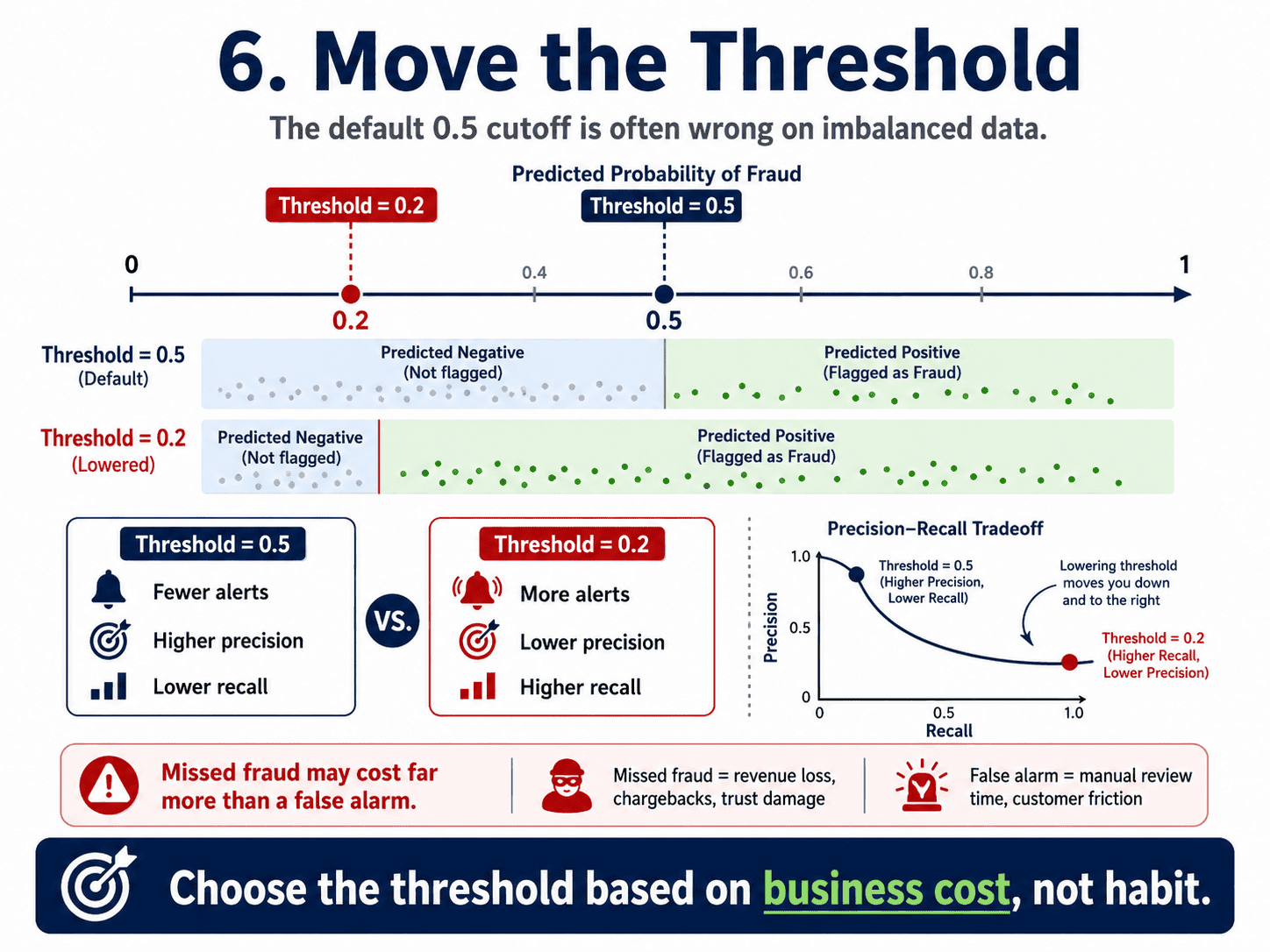
6. Move the Threshold:
Recall from Day 5: Logistic Regression — When the Answer is Yes or No that the default threshold in Logistic Regression is 0.5. With imbalance, that default is almost always wrong.
If we lower the threshold (say to 0.2):
- The model flags more transactions as fraud.
- Recall goes up (catch more fraud).
- Precision goes down (more false alarms).
Adjusting the threshold is the cheapest and most underrated fix.
probabilities = model.predict_proba(X_test)[:, 1]
predictions = (probabilities >= 0.2).astype(int)
We drive this by business cost: "A missed fraud costs $5,000. A false alarm costs $5 of analyst time. Choose accordingly."
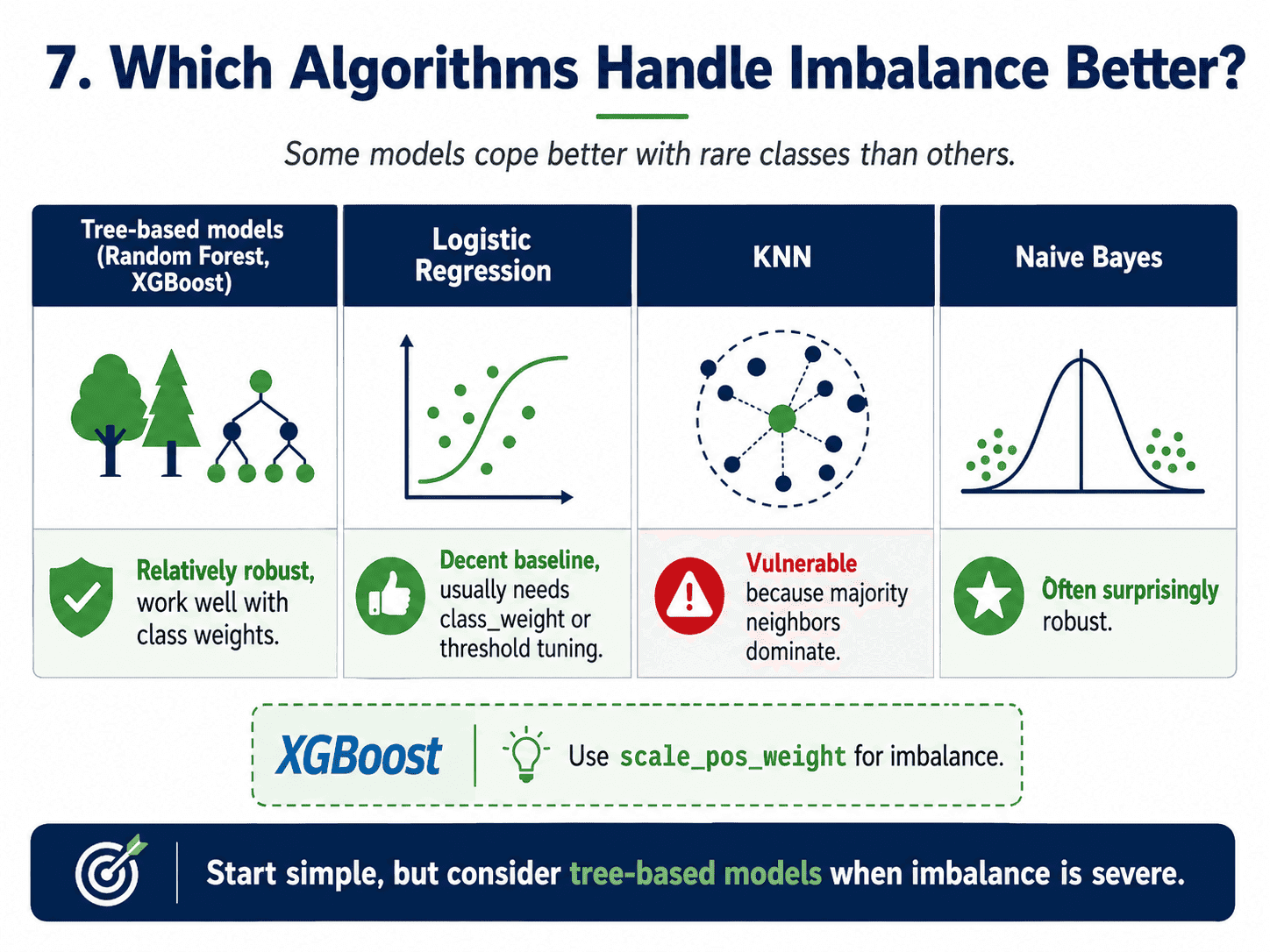
7. Pick Algorithms That Handle Imbalance Well:
Some models cope better than others.
- Tree-based models (Random Forest, XGBoost): relatively robust, especially with
class_weightorscale_pos_weight. - Logistic Regression: needs help (
class_weightor threshold tuning). - KNN: vulnerable, since majority neighbours always outnumber the rare ones.
- Naive Bayes: surprisingly robust due to its probabilistic nature.
XGBoost in particular has a built-in scale_pos_weight parameter.
import xgboost as xgb
ratio = sum(y_train == 0) / sum(y_train == 1)
model = xgb.XGBClassifier(scale_pos_weight=ratio)
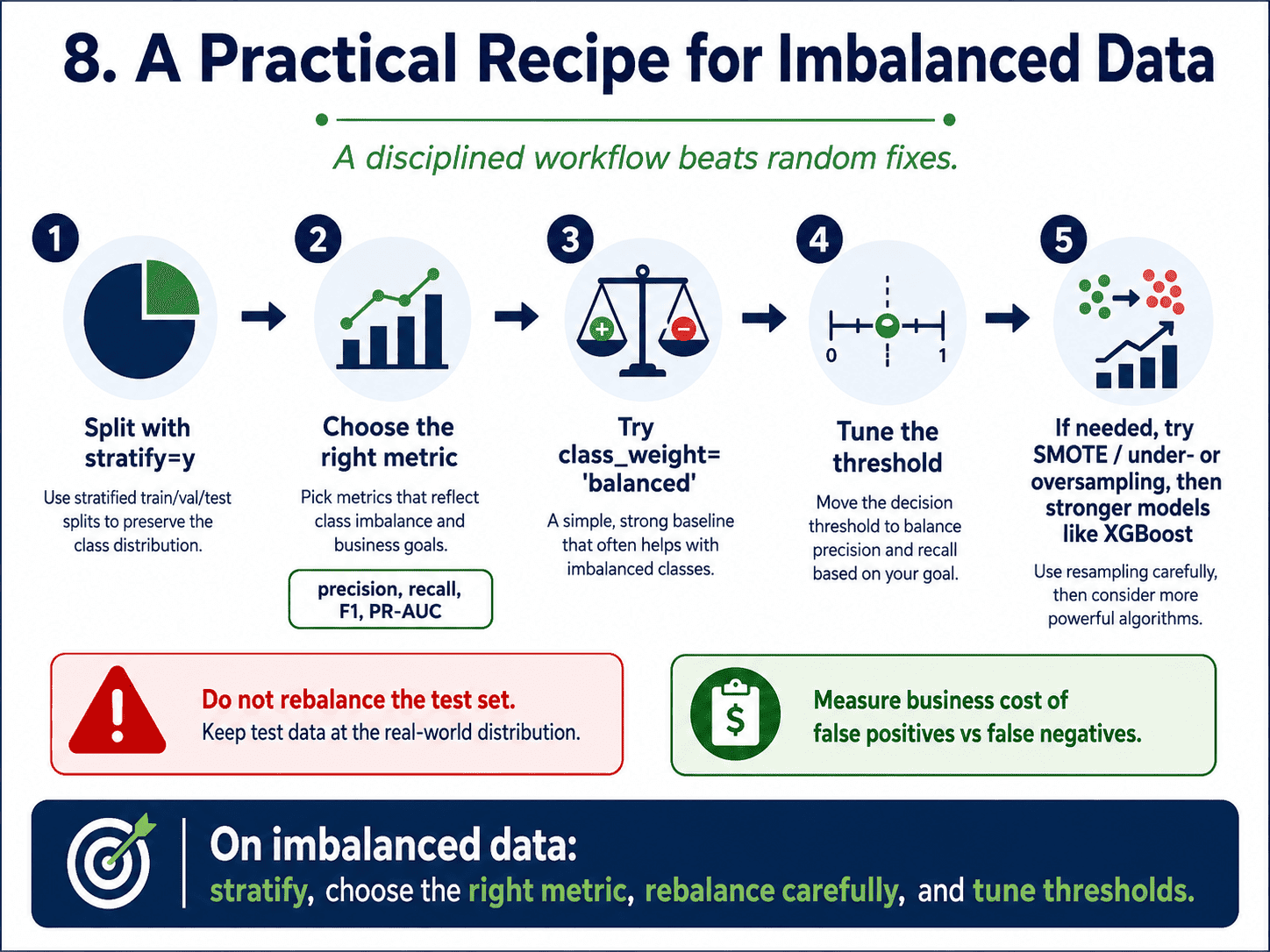
8. The Practical Recipe:
The disciplined order to try things.
- Start with
class_weight='balanced'. Set the right metric (F1, recall, or PR-AUC). - Tune the threshold using a precision-recall curve.
- If still not enough, try SMOTE or under/over-sampling.
- Switch to gradient boosting if we are not already there.
- Combine. SMOTE plus XGBoost plus threshold tuning is a very common production recipe.
We should avoid throwing every technique at the problem at once, because then we will not know what helped.
9. The Code (Realistic Workflow):
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42 # stratify is crucial
)
model = LogisticRegression(class_weight='balanced', max_iter=1000)
model.fit(X_train, y_train)
probs = model.predict_proba(X_test)[:, 1]
preds = (probs >= 0.3).astype(int) # custom threshold
print(classification_report(y_test, preds))
The stratify=y part keeps the test set's imbalance the same as the original data, which is critical for honest evaluation.
A small thought to sit with. Suppose our model on a 99/1 imbalanced dataset has recall 0.9 and precision 0.1. We catch 90% of fraud but 90% of our alerts are false alarms.
The team is drowning in noise.
What would we change?
Raise the threshold. Recall will drop (catch less fraud) but precision will rise (fewer false alarms).
We drive the tradeoff with business cost. Plot a precision-recall curve and pick the point that matches business reality.
10. A Few Common Confusions Cleared:
- Why apply SMOTE only on training? Because the test set must reflect what production looks like. SMOTE on test would give us fake test data and an unrealistic score.
- Is undersampling ever better than oversampling? Yes, on huge datasets where the majority class still has plenty of examples after undersampling. Faster training, less memory.
- Does class_weight='balanced' guarantee great results? No, but it is a free baseline. Always try it first before reaching for SMOTE.
- Why is ROC-AUC sometimes misleading on imbalance? Because the false positive rate has a huge denominator (the majority class). The score can look high while precision is awful. PR-AUC focuses on the rare class and is more honest.
- Common interview question: "You have 99% accuracy on fraud detection. What is wrong?" Almost certainly imbalance. Look at the confusion matrix; the model is probably predicting "not fraud" for everything. Discuss precision, recall, class weights, and threshold tuning to score full marks.
11. If This Came In An Interview:
A few questions to be ready for, with one-line answers.
- You have 99% accuracy on fraud detection. What is wrong? Almost certainly imbalance. The model is probably predicting "not fraud" for everything. We should look at the confusion matrix, precision, recall, and F1.
- How would you handle class imbalance? A practical order: (1) pick the right metric (F1, PR-AUC, recall), (2) use
class_weight='balanced', (3) tune the threshold, (4) try SMOTE or under/oversampling, (5) switch to a tree-based model if not already. - What is SMOTE and why do we apply it only on training? Synthetic Minority Over-sampling. It creates new minority examples by interpolating between existing ones. Applied only on training, because the test set must reflect the real-world distribution.
- What does class_weight='balanced' do? It tells the model to penalise mistakes on the rare class more heavily. Free baseline fix, often as good as resampling.
- Why does threshold tuning matter on imbalanced data? Because the default 0.5 is almost always wrong. Lowering it catches more positives at the cost of more false alarms. We pick based on the business cost of each error type.
- Why is ROC-AUC misleading on heavy imbalance, and what do you use instead? ROC-AUC's denominator (False Positive Rate) is dominated by the majority class, which inflates the score. PR-AUC focuses on the rare class and is more honest.
- Why is stratify=y essential when splitting imbalanced data? Because without it, the rare class can be over- or under-represented in the test set by chance, giving an unreliable score.
- Which models handle imbalance well? Tree-based models (Random Forest, XGBoost) cope better than linear ones. XGBoost has a
scale_pos_weightparameter built in for this.
12. Summing It Up:
If we remember one thing from today, it is this: on imbalanced data, accuracy lies. Always check the confusion matrix.
Pick metrics that focus on the rare class (precision, recall, F1, PR-AUC). Fix imbalance with class weights first, threshold tuning next, SMOTE or under/oversampling after that.
Tree-based models handle imbalance more gracefully than linear ones. And stratify=y in our train-test split is non-negotiable.
Coming Up on Day 12: K-Nearest Neighbors — Tell Me Who Your Friends Are
Eleven days of fundamentals and the two regression friends. From tomorrow, we sprint through the classic supervised classifiers, starting with the friendliest of them all: K-Nearest Neighbours. No training, no equations, just memory and distance.
That's all for today. Let's meet up again tomorrow with Day 12.
Thanks for reading.
Cheers!