Day 10: Cross-Validation & Hyperparameter Tuning
Day 10: Cross-Validation & Hyperparameter Tuning
 Parathan Thiyagalingam
Parathan Thiyagalingam
We have casually said "use cross-validation" for three days now. Today we finally explain it properly, along with the related question of how to find the best hyperparameters. Together, these two ideas are the backbone of every disciplined ML project, and they show up in interviews more than almost anything else after the algorithms themselves.
This blog post is a daily learning summary of my ML self-study.
Terms Used Today
- Cross-validation (CV): Average a model's score over many train/test splits, so the result is more honest than from a single split.
- K-fold CV: Split data into K parts, hold one out at a time, train on the rest, repeat K times, average the scores.
- Stratified K-fold: Keep class proportions equal across folds. Use this for classification.
- Parameter: Learned by the algorithm during training (β coefficients, tree splits).
- Hyperparameter: Set by us before training (learning rate, max depth, k in KNN).
- GridSearchCV: Try every combination of hyperparameters in a grid.
- RandomizedSearchCV: Sample random combinations from the grid. Usually as good as GridSearch for less compute.
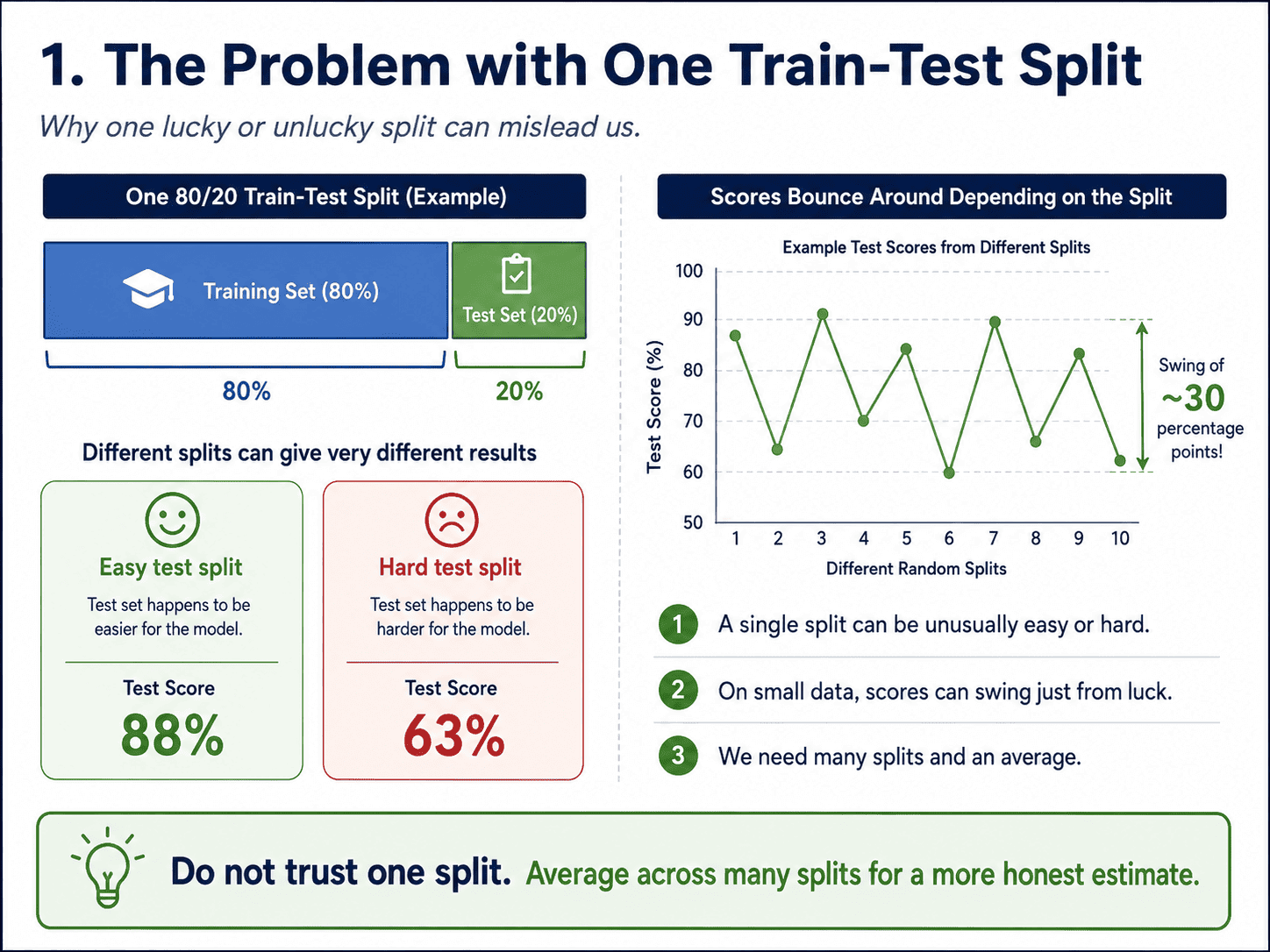
1. The Problem with One Train-Test Split:
Day 2: Train-Test Split & The Sin of Overfitting told us to split 80/20, train on 80%, evaluate on 20%.
But what if that 20% happened to be unusually easy? Or unusually hard? We would get a misleading score either way. On small datasets, this swing can be brutal: a 5% accuracy difference based purely on luck of the draw.
The solution is to not trust a single split. We use many splits and average them.
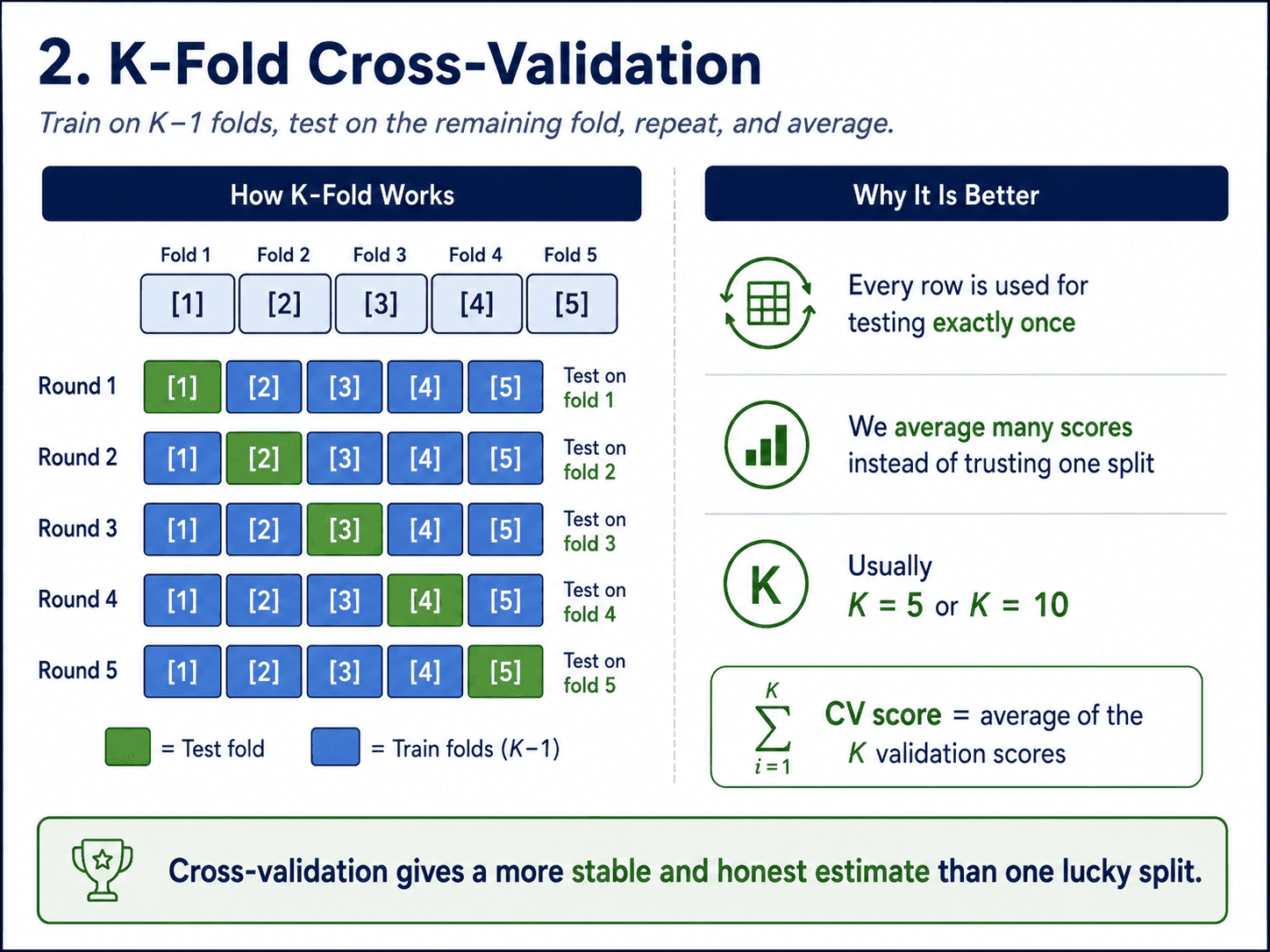
2. K-Fold Cross-Validation:
Split the training data into K equal pieces, called folds. Usually K = 5 or K = 10. Then K times:
- Hold one fold out as a mini test set.
- Train on the remaining K minus 1 folds.
- Score the model on the held-out fold.
At the end, average all K scores. That is our cross-validated score.
Picture K = 5:
Fold: [1][2][3][4][5]
Round 1: test on [1], train on [2][3][4][5]
Round 2: test on [2], train on [1][3][4][5]
Round 3: test on [3], train on [1][2][4][5]
Round 4: test on [4], train on [1][2][3][5]
Round 5: test on [5], train on [1][2][3][4]
Every row eventually gets to be in the test set exactly once. Much more honest than a single split.
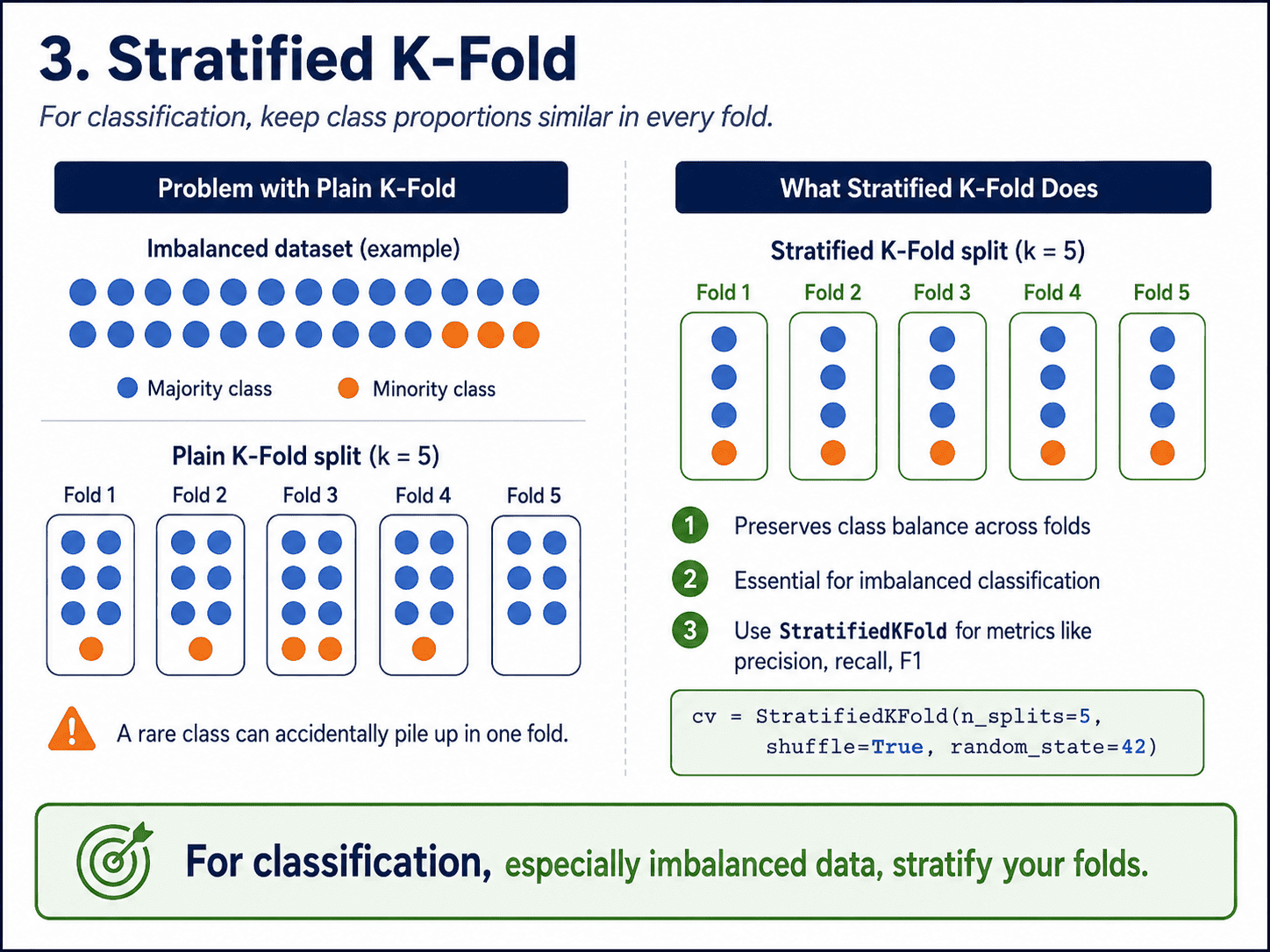
3. Stratified K-Fold:
For classification with imbalanced classes, plain K-fold can accidentally drop all the rare-class examples into one fold. Stratified K-fold ensures each fold has the same class proportions as the overall data. Always use it for classification.
from sklearn.model_selection import cross_val_score, StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X_train, y_train, cv=cv, scoring='f1')
print(scores.mean(), scores.std())
The mean tells us the typical score. The standard deviation tells us how stable the model is.
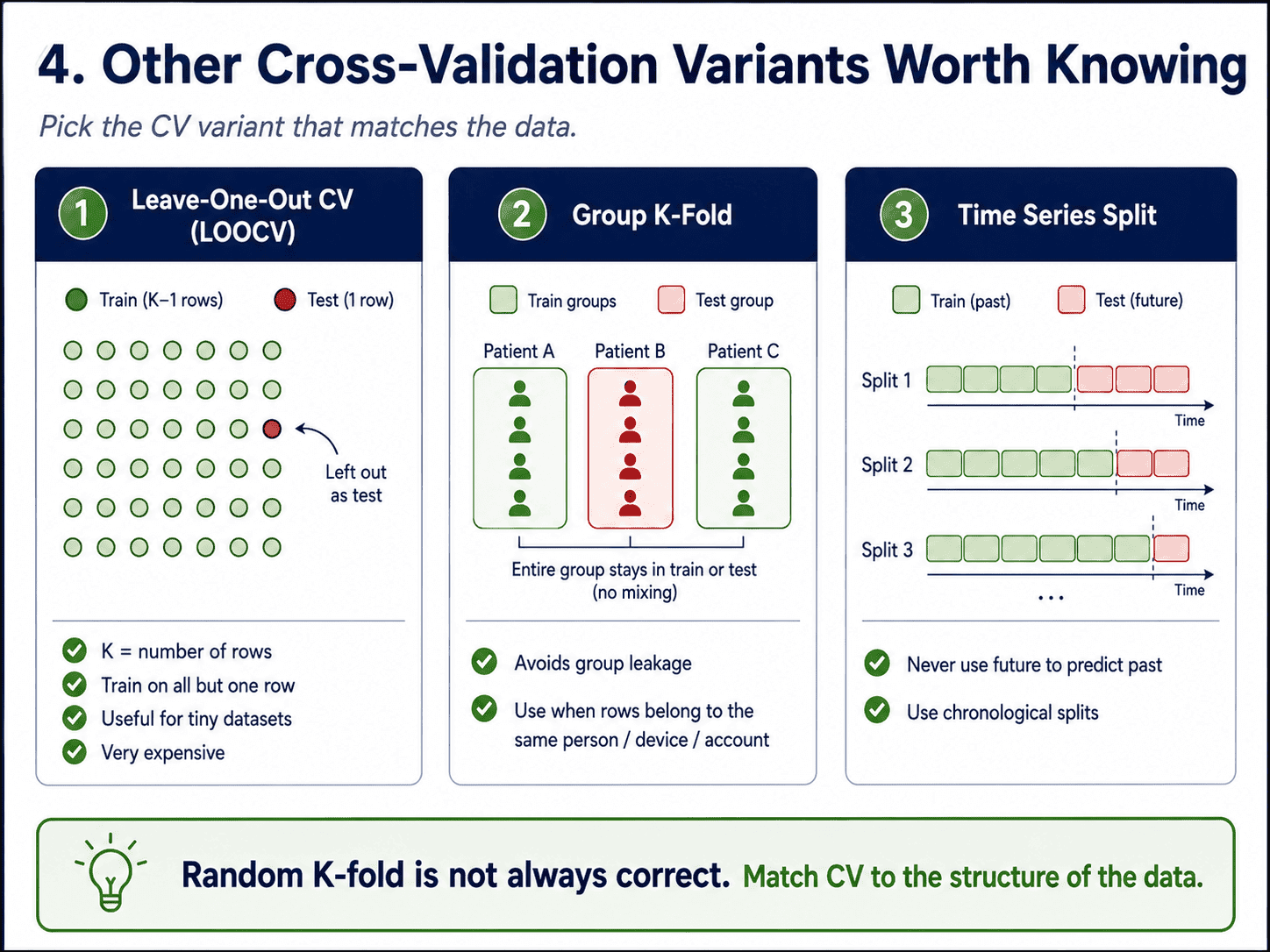
4. Other Variants Worth Knowing:
- Leave-One-Out CV (LOOCV). K equals the number of rows. Train on all but one row, test on that one row, repeat. Expensive but useful for tiny datasets.
- Group K-Fold. When rows belong to groups (for example, several measurements per patient), we make sure no group spans both train and test, otherwise we leak.
- Time Series Split. For time-series data, we never use future to predict past. We walk forward through time instead of shuffling randomly.
Picking the right CV variant matters. Random K-fold on time-series data is a classic leakage bug.
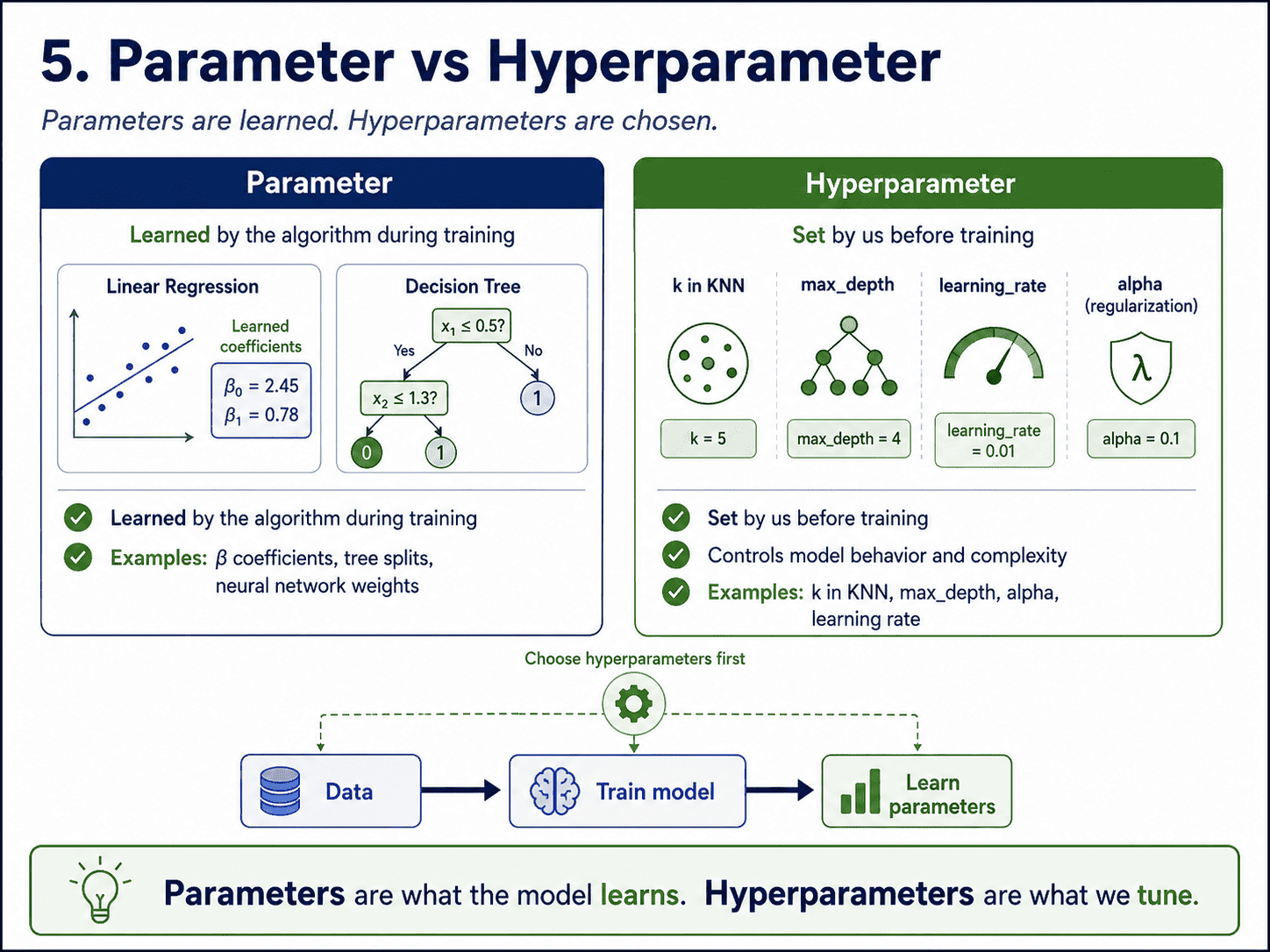
5. Parameter vs Hyperparameter:
A subtle but heavily asked distinction.
| Term | Set by | Examples |
|---|---|---|
| Parameter | The learning algorithm (from data) | β₀, β₁ in Linear Regression; splits in a tree |
| Hyperparameter | Us (before training) | Learning rate, α in Ridge, k in KNN, max_depth |
In short: parameters are what the model learns, and hyperparameters are what we choose. Tuning hyperparameters is one of the most common ML tasks, and CV is how we evaluate each setting fairly.
6. Grid Search:
Define a grid of hyperparameter values, try every combination, pick the best.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
param_grid = {
'n_estimators': [100, 300, 500],
'max_depth': [5, 10, 20, None],
'min_samples_split': [2, 5, 10]
}
grid = GridSearchCV(
RandomForestClassifier(),
param_grid,
cv=5, scoring='f1', n_jobs=-1
)
grid.fit(X_train, y_train)
print(grid.best_params_, grid.best_score_)
Exhaustive. Reliable. Slow. The example above has 3 × 4 × 3 = 36 combinations, each evaluated with 5-fold CV, which is 180 model fits. Costly for big models.
7. Random Search:
Instead of trying every combination, sample N random combinations from the grid.
from sklearn.model_selection import RandomizedSearchCV
search = RandomizedSearchCV(model, param_distributions, n_iter=50, cv=5)
A famous research result (Bergstra and Bengio). On most realistic problems, random search finds nearly as good a configuration as grid search, in a fraction of the time. Because in most cases, only a few hyperparameters truly matter, and random sampling explores them well.
A rule of thumb worth remembering. Default to RandomSearch. Use GridSearch only after we have narrowed the range and want exhaustive verification.

8. Smarter Search (Just to Be Aware):
Tools like Optuna, Hyperopt, and scikit-optimize learn from previous trials to pick promising next ones. Often 2 to 5 times more efficient than random search on big problems. Worth knowing the name exists. Not always worth the setup for small projects.
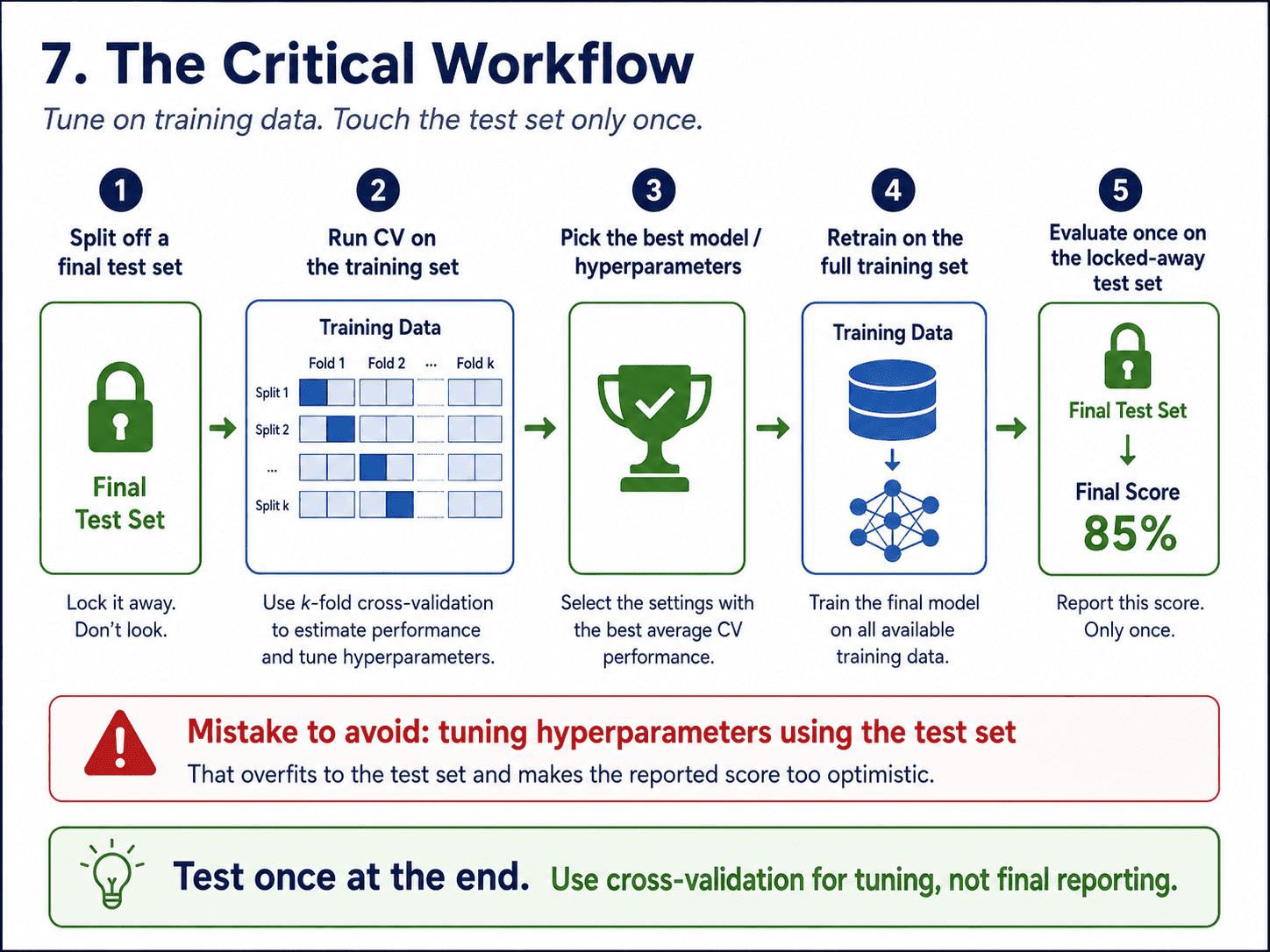
9. The Critical Workflow (and the One Mistake to Avoid):
Here is the disciplined process.
- Split off a final test set right at the start. Lock it away.
- Run CV on the training set to compare models or tune hyperparameters.
- Pick the best configuration.
- Retrain on the entire training set.
- Evaluate exactly once on the locked-away test set. That is our honest performance estimate.
The cardinal sin is tuning hyperparameters using the test set. If we do that, we have overfitted to the test set, and our reported score becomes optimistic fantasy.
10. The Code (All-in-One):
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
pipe = Pipeline([('scaler', StandardScaler()), ('model', Ridge())])
params = {'model__alpha': [0.001, 0.01, 0.1, 1, 10, 100]}
grid = GridSearchCV(pipe, params, cv=5, scoring='r2')
grid.fit(X_train, y_train)
print("Best α:", grid.best_params_)
print("CV R²:", grid.best_score_)
print("Test R²:", grid.score(X_test, y_test)) # honest final score
Notice the pipeline plus GridSearch combo. The scaling happens inside each CV fold, which avoids leakage.
A small thought to sit with. Suppose we run 5-fold CV and get scores [0.91, 0.92, 0.89, 0.90, 0.91] for Model A, and [0.95, 0.85, 0.96, 0.78, 0.97] for Model B.
The averages are almost equal (0.906 vs 0.902).
Which would we ship?
Model A. Same average, but lower variance, which means more reliable performance.
Model B is a gambler. We do not want a model whose score depends on which slice of data it sees in production. Always look at both the mean and the standard deviation of CV scores.

11. A Few Common Confusions Cleared:
- How big should K be? 5 or 10 is standard. Higher K means more reliable estimates but more compute. K = 10 is the textbook gold standard.
- Is CV computationally expensive? Yes. K full trainings per hyperparameter combo. For huge data and slow models, people often use K = 3 or do hold-out tuning on a single validation set.
- Should I CV the test set too? No. The test set is touched exactly once at the end. CV is for tuning, not for final reporting.
- What about Nested CV? Outer loop estimates true generalisation, inner loop tunes hyperparameters. The most rigorous and most expensive option. Useful for research papers, usually overkill for industry.
- Common interview question: "What is the difference between a parameter and a hyperparameter?" Parameters are learned by the algorithm during training. Hyperparameters are chosen by us before training. Confusing them is a red flag.
12. If This Came In An Interview:
A few questions to be ready for, with one-line answers.
- Why is a single train/test split not enough? Because the score depends on which rows happened to land in the test set. On small data, the swing can be 5% or more purely from luck. CV averages over many splits to remove this noise.
- What is K-fold cross-validation? Split the training data into K equal parts. Train on K-1 of them, test on the remaining one, rotate, and average the K scores.
- What is Stratified K-fold? A K-fold variant that keeps class proportions equal across all folds. Use it for classification, especially on imbalanced data.
- What is the difference between a parameter and a hyperparameter? Parameters are learned by the algorithm during training (β coefficients, tree splits). Hyperparameters are set by us before training (learning rate, max_depth, k in KNN).
- GridSearchCV vs RandomizedSearchCV? Grid tries every combination (exhaustive but slow). Random samples N combinations (usually nearly as good for a fraction of the compute). Default to Random Search.
- Why do we keep a separate test set even when using CV? Because tuning hyperparameters with CV slightly fits the model to the validation folds. The test set, touched only once at the end, gives the honest final score.
- What is nested CV and when would you use it? An outer CV loop estimates true generalisation, an inner loop tunes hyperparameters. Most rigorous, most expensive. Used in research and high-stakes settings.
- How do you choose K for K-fold? 5 or 10 are standard. Higher K means more reliable estimates but more compute. 10 is the textbook gold standard.
13. Summing It Up:
If we remember one thing from today, it is this: never trust a single split, and never touch the test set while tuning. K-fold CV uses many splits and averages. We tune hyperparameters inside CV using RandomSearch (the default) or GridSearch (exhaustive), then evaluate exactly once on the locked-away test set. Parameters are learned. Hyperparameters are chosen.
Coming Up on Day 11: Class Imbalance — Why Accuracy Lies
A 99% accurate fraud detector that always says "not fraud" is, technically, 99% accurate. Tomorrow we tackle why that is a disaster, and what to do about it. Class imbalance is a favourite interviewer trap and one of the most common real-world ML problems.
That's all for today. Let's meet up again tomorrow with Day 11.
Thanks for reading.
Cheers!