Day 1: What is RAG and Why do we need It?
RAG enhances LLMs by providing relevant data during question answering, overcoming limitations like hallucinations and lack of private data access.
 Parathan Thiyagalingam
Parathan Thiyagalingam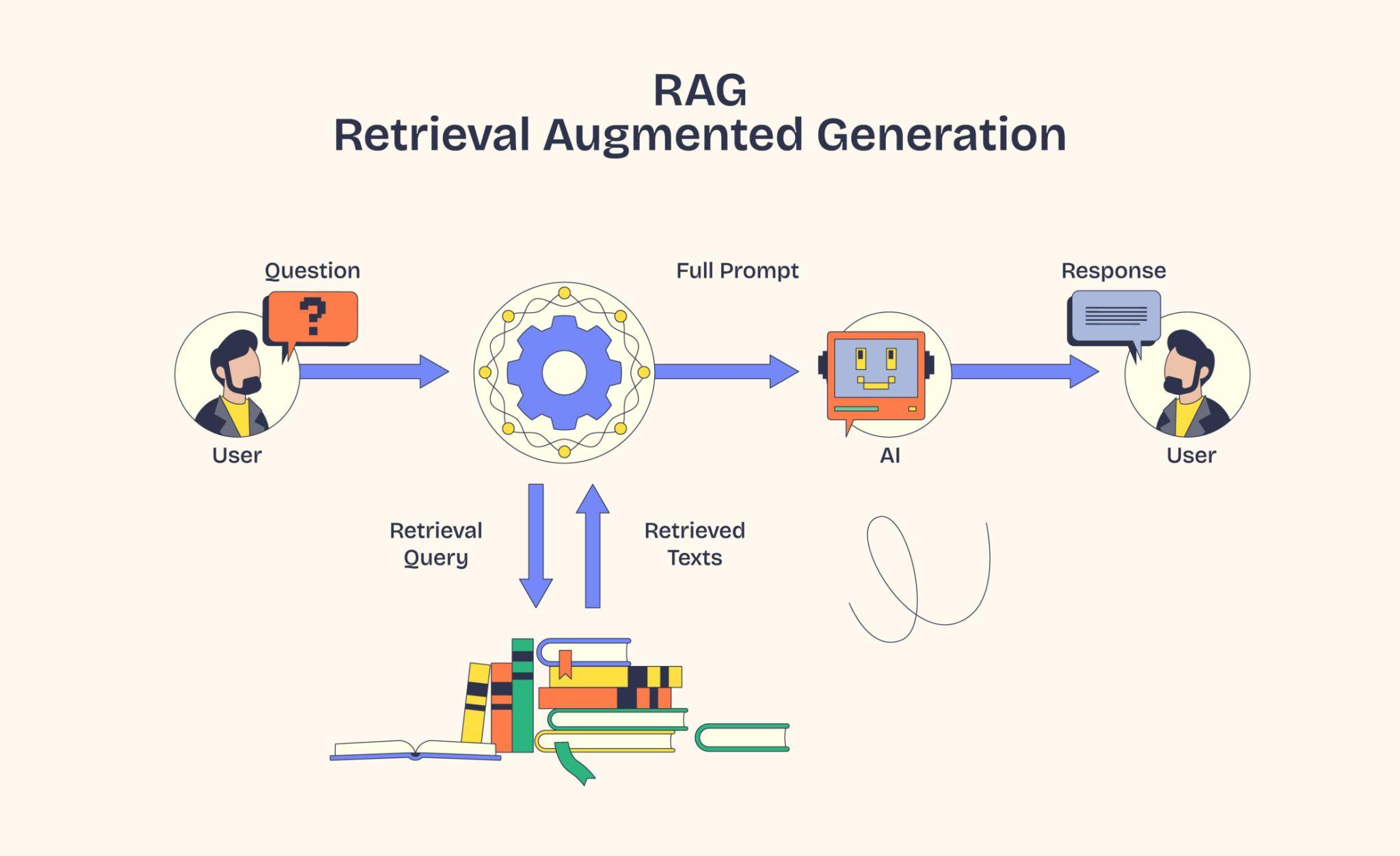
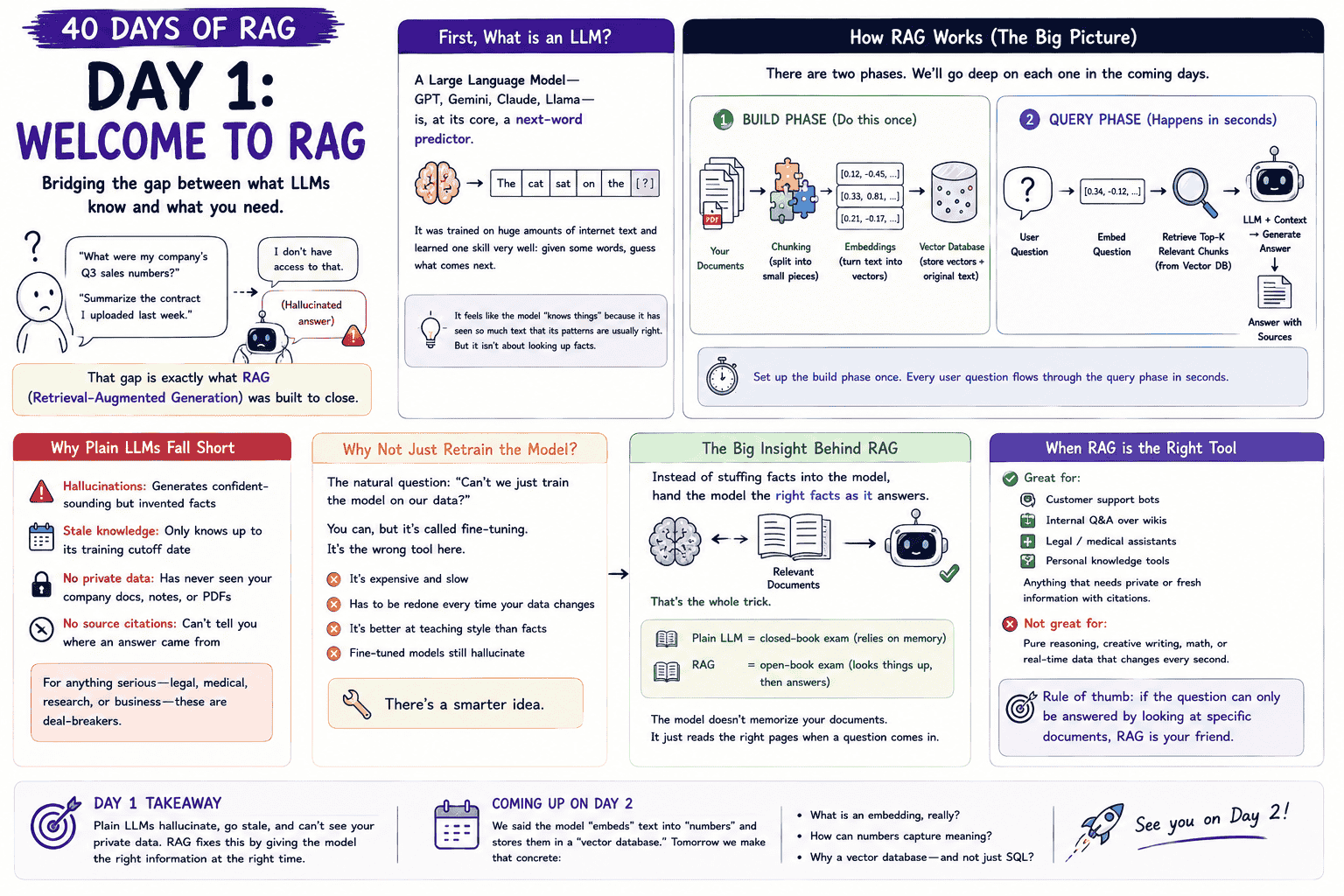
If you have asked ChatGPT something like, "What were my company's Q3 sales numbers?" or "Summarise the contract I uploaded last week", you have probably seen one of two outcomes. Either a confidently wrong answer (a hallucination) or a polite "I don't have access to that". That gap is what RAG (Retrieval-Augmented Generation) was built to close.
This post kicks off a 40-day learning series on RAG. Today, we cover the very basics. What an LLM actually does, why it falls short on its own, and where RAG fits.
This blog post is a daily learning summary of my 40-day RAG class from Syed Jaffer of Parotta Salna.
Terms Used Today
- LLM (Large Language Model): A model trained on huge amounts of text that predicts the next word, given some words.
- Hallucination: A confidently wrong answer the model invents because it has no real source for the fact.
- Fine-tuning: Continuing to train a model on your own data so it picks up new styles or facts. Expensive, slow, and the wrong tool for adding fresh information.
- RAG (Retrieval-Augmented Generation): A pattern where the model is given the relevant text at question time, instead of being trained on it.
- Build phase: The one-time setup where documents are split, embedded, and stored in a vector database.
- Query phase: The fast loop that runs on every user question, pulling the right chunks and handing them to the model.
1. What is an LLM?
A Large Language Model (GPT, Gemini, Claude, Llama) is, at its core, a next-word predictor. It was trained on huge amounts of internet text and learned one skill very well. Given some words, guess what comes next.
It feels like the model "knows things" because it has seen so much text that its patterns are usually right. But it is not actually looking up facts. Hold onto that idea. Every weakness below comes straight from it.
2. Why Plain LLMs Fall Short:
Four weaknesses keep showing up when we ask a plain LLM something important.
- Hallucinations: It generates confident-sounding but invented facts.
- Stale knowledge: It only knows up to its training cutoff date.
- No private data: It has never seen your company docs, notes, or PDFs.
- No source citations: It cannot tell you where an answer came from.
For anything serious like legal, medical, research, or business use, these four are deal-breakers.
3. Why Not Just Retrain the Model?
The natural question. "Can we not just train the model on our data?"
You can. It is called fine-tuning. The problem is that fine-tuning is the wrong tool for this job. It is expensive; it is slow; it has to be redone every time your data changes; and it is better at teaching the model style than facts. Fine-tuned models still hallucinate.
There is a smarter idea.
4. The Big Insight Behind RAG:
Instead of stuffing facts into the model, hand the model the right facts as it answers. That is the whole trick.
A simple way to picture it:
- Plain LLM is a closed-book exam. The student relies on memory.
- RAG is an open-book exam. The student looks things up, then answers.
The model does not memorise your documents. It just reads the right pages when a question comes in.
5. How RAG Works in Two Phases:
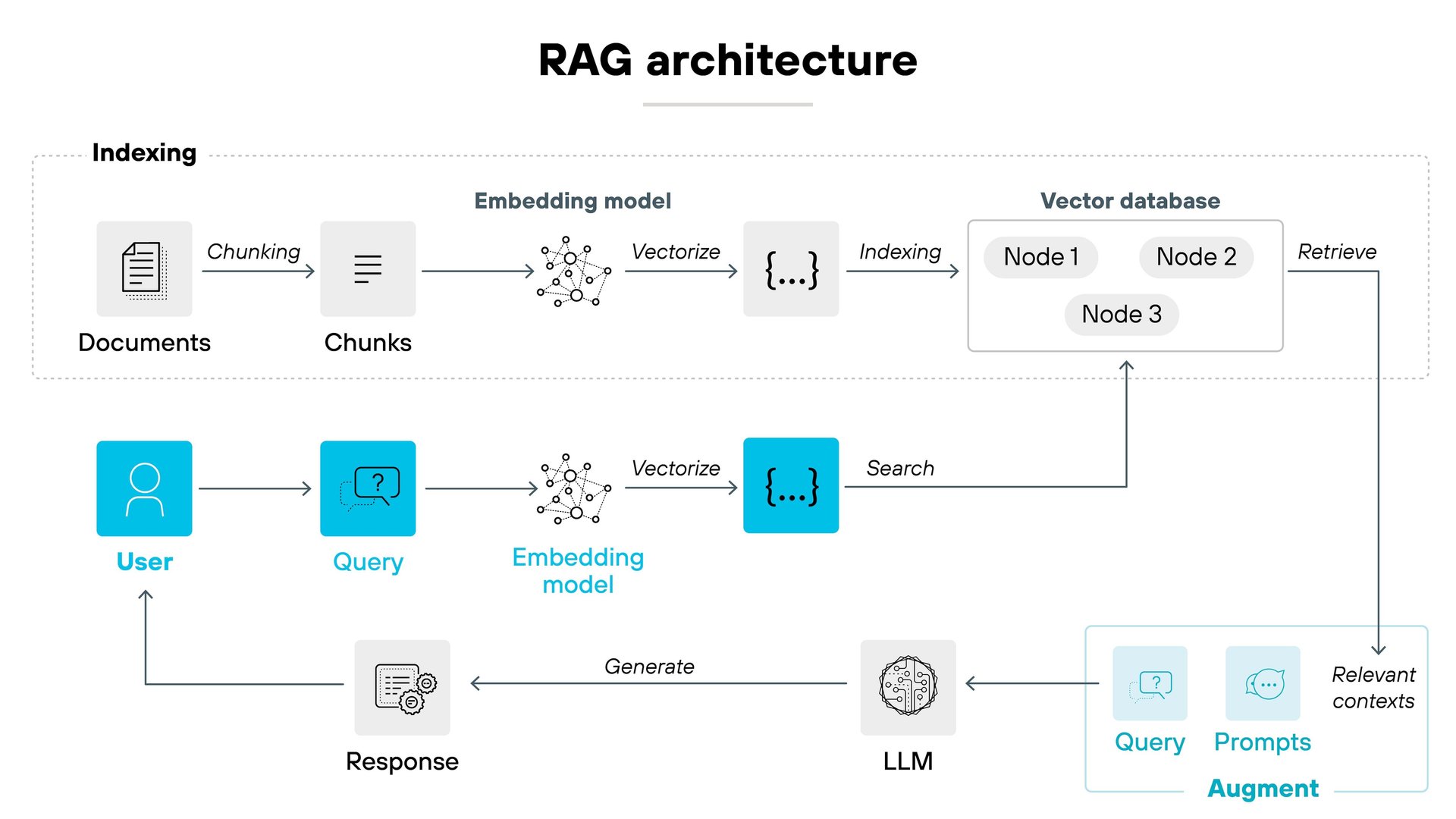
A RAG system runs in two phases. We will go deep on each one in the coming days.
- Build phase (one-time setup). Take your documents, split them into chunks, turn each chunk into an embedding (a list of numbers that captures meaning), and store everything in a vector database alongside the original text.
- Query phase (runs on every question). When a user asks a question, turn it into an embedding too. Look up the closest chunks in the vector database. Hand those chunks, along with the question, to the LLM and let it write the final answer.
Set up the build phase once. Every user question flows through the query phase in seconds.
6. When RAG is the Right Tool:
RAG shines when the answer depends on specific documents rather than general knowledge.
- Good fit: customer support bots, internal Q&A over wikis, legal and medical assistants, personal knowledge tools, anything that needs private or fresh information with citations.
- Not a good fit: pure reasoning puzzles, creative writing, maths problems, or real-time data that changes every second.
A simple rule of thumb. If the question can only be answered by looking at specific documents, RAG is your friend.
7. If This Came In An Interview:
- What does RAG stand for, and what does it solve? Retrieval-Augmented Generation. It gives an LLM the right documents at question time so the model can answer with private or fresh information rather than guess.
- Why not just fine-tune the model on your data? Fine-tuning is expensive; it is slow, has to be redone whenever data changes, and is better at teaching style than facts. Fine-tuned models still hallucinate.
- What is a hallucination? A confident-sounding but invented answer the model produces because it has no real source for the fact.
- What are the two phases of a RAG system? A one-time build phase (chunk, embed, store) and a per-query query phase (embed the question, retrieve top chunks, ask the LLM).
- When is RAG a bad choice? Pure reasoning, math, creative writing, or anything that does not need to be grounded in specific documents.
8. Summing It Up:
If we remember one thing from today, it is this: plain LLMs hallucinate, go stale, and cannot see your private data. RAG fixes this by giving the model the right information at the right time.
That shift, from "memorise everything" to "look it up when needed", is the entire foundation of the next 39 days.
Coming Up on Day 2
We said the model "embeds" text into "numbers" and stores them in a "vector database". Tomorrow we make concrete. What is an embedding, really? How can numbers capture meaning? And why a vector database instead of plain SQL?
That's all for today. Let's meet up again tomorrow with Day 2.
Thanks for reading.
Cheers!